Prim
Prim은 무방향 가중치 그래프에서 최소 신장 트리(MST)를 구하는 알고리즘입니다. 임의의 정점에서 시작하여, 현재까지 구성된 트리와 인접한 간선들 중 가중치가 가장 낮은 간선을 선택하고, 그 간선을 통해 아직 트리에 포함되지 않은 정점을 하나씩 추가함으로써, 트리를 점진적이고 연속적인 방식으로 확장해 나갑니다.
- 매 단계마다 트리에 포함되지 않은 정점 중 가장 가까운 정점을 선택하기 때문에,
Greedy특성을 가집니다.
“트리를 연속적으로 확장한다”의 의미는 탐색 시작 이후 항상 하나의 연결된 컴포넌트를 유지하며 정점을 확장해나간다는 것을 의미합니다.
Mechanism
Prim 알고리즘은 아래 과정으로 동작합니다.
초기화: 임의의 정점 하나를 선택해 MST(최소 신장 트리)에 포함시킵니다.간선 선택(Greedy Choice): MST에 포함된 정점과 외부의 정점을 연결하는 간선들 중, 가중치가 가장 낮은 간선을 선택하고, 간선과 연결된 정점이 MST에 포함되지 않은 경우에만 정점을 MST에 추가합니다.반복: 모든 정점이 MST에 포함될 때까지 2번 과정을 반복합니다.
이제 아래 그래프를 기준으로 최소 신장 트리(MST)를 직접 구해보겠습니다.
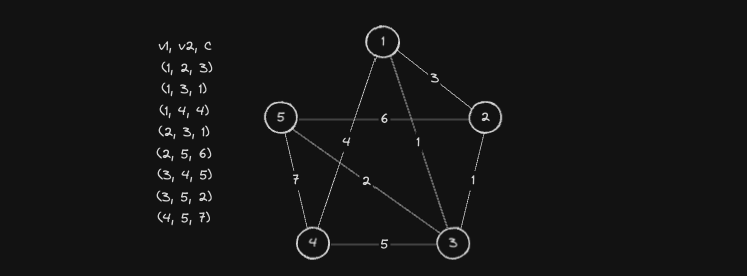
가장 먼저, 임의의 정점 하나를 선택해 MST(최소 신장 트리)에 포함시킵니다.
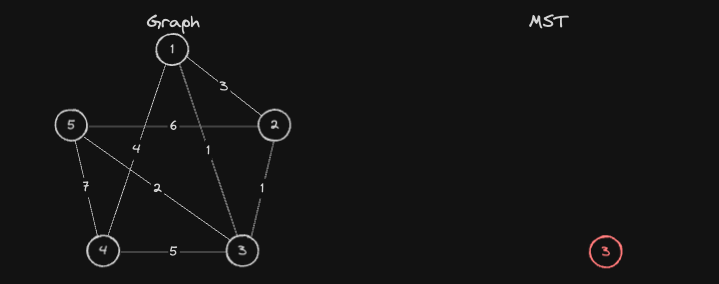
현재 MST에 포함된 정점들 3번과 연결된 간선 중, 가장 가중치가 낮은 간선을 선택하고, 이 간선과 연결된 정점이 아직 MST에 포함되지 않았다면, 해당 정점을 MST에 추가합니다.
- 즉,
1번노드를 MST에 포함시킵니다. - 가중치가 동일한 간선이 있으면, 아무거나 MST에 포함시킵니다.
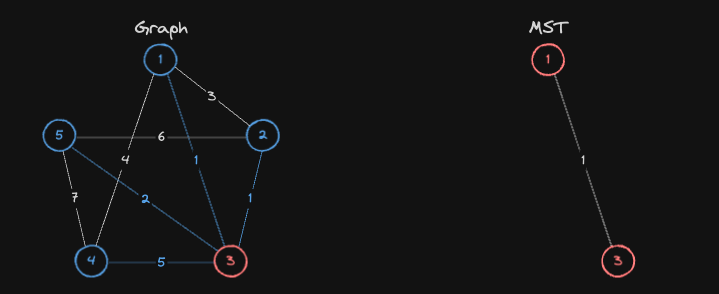
현재 MST에 포함된 정점들 3, 1번과 연결된 간선 중, 가장 가중치가 낮은 간선을 선택하고, 이 간선과 연결된 정점이 아직 MST에 포함되지 않았다면, 해당 정점을 MST에 추가합니다.
- 즉,
2번노드를 MST에 포함시킵니다.
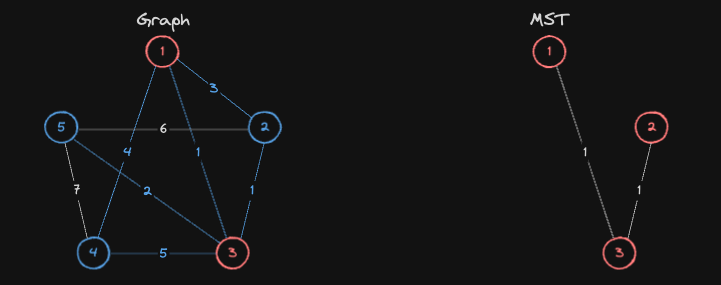
현재 MST에 포함된 정점들 3, 1, 2번과 연결된 간선 중, 가장 가중치가 낮은 간선을 선택하고, 이 간선과 연결된 정점이 아직 MST에 포함되지 않았다면, 해당 정점을 MST에 추가합니다.
- 즉,
5번노드를 MST에 포함시킵니다.
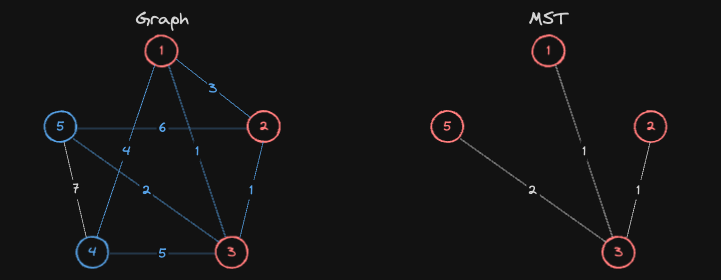
현재 MST에 포함된 정점들 3, 1, 2, 5번과 연결된 간선 중, 가장 가중치가 낮은 간선을 선택하고, 이 간선과 연결된 정점이 아직 MST에 포함되지 않았다면, 해당 정점을 MST에 추가합니다.
- 즉,
4번노드를 MST에 포함시킵니다.
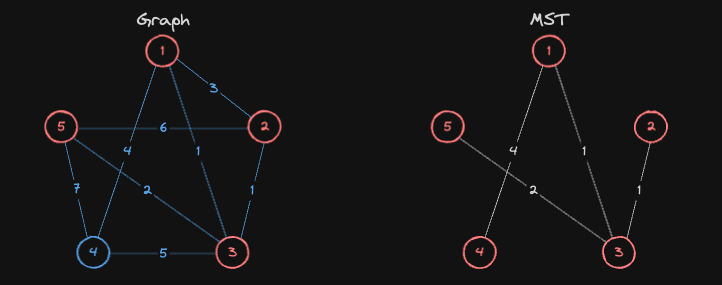
주어진 그래프의 모든 정점이 MST에 포함되었기 때문에, Prim알고리즘이 종료됩니다. 따라서 주어진 그래프에서 최소 신장 트리는 가중치의 합이 8인 부분 그래프가 됩니다.
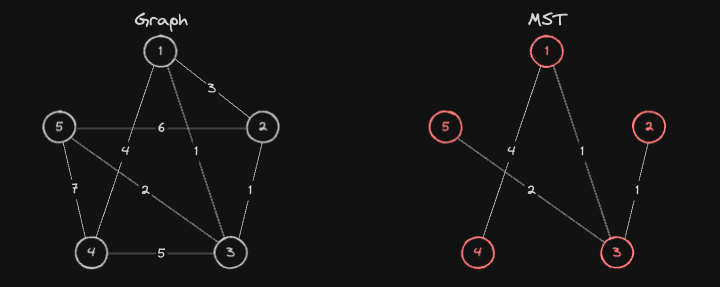
Diff Between Kruskal
크루스칼 알고리즘은 전체 간선을 가중치 오름차순으로 정렬한 뒤, 가장 짧은 간선부터 하나씩 선택해나가는 방식입니다. 이때 간선이 그래프 전역에 흩어져 있을 수 있기 때문에, MST에 추가되는 간선들이 항상 서로 이어져 있지는 않습니다. 즉, MST가 중간에 여러 조각으로 나뉘어 있다가 나중에 하나로 합쳐지는 형태가 될 수 있으며, 이 때문에 MST가 불연속적으로 확장되는 특성을 가집니다.
간선을 기준으로 동작합니다.
반면 프림 알고리즘은 하나의 정점에서 시작해, 현재까지 구성된 MST에 포함된 정점들과 연결된 간선 중 가장 가중치가 낮은 것만을 선택해 연결된 정점을 MST에 추가해 트리를 확장해나갑니다. 항상 MST 내부 정점과 외부 정점 간의 연결만 고려하기 때문에 MST가 항상 하나의 연결된 구성을 유지한 채 연속적으로 확장되는 특성을 가집니다.
정점을 기준으로 동작합니다.
| 항목 | Prim | Kruskal |
|---|---|---|
| 접근 방식 | 정점 중심 | 간선 중심 |
| 사용 자료구조 | Priority Queue(우선순위 큐: 최소 힙) | Disjoint Set(서로소 집합) & Union-Find |
| 그래프 표현 | 인접 리스트 또는 인접 행렬 | 간선 리스트 |
| 간선 선택 방식 | MST에 연결된 간선 중 가장 가중치가 작은 간선 선택 | 전체 간선 중 가중치가 가장 작은 간선 선택 |
| 사이클 관리 | 명시적으로 사이클 관리하지 않음, 연결된 컴포넌트 관리 | Union-Find로 사이클 여부 판단 및 방지 |
| 확장 방식 | 하나의 연결된 컴포넌트를 유지하며 정점을 확장 (연속적) | 여러 트리에서 시작해 간선을 추가하며 하나의 트리로 합침 (불연속적) |
| 시간 복잡도 | 인접리스트+힙 : O(E log V) 인접행렬 : O(V²) | O(E log E) |
| 메모리 사용 | 우선순위 큐로 메모리 사용 많을 수 있음 | 간선을 정렬한 뒤 사용하면 메모리 적게 사용 가능 |
| 시작점 필요 | 임의의 시작 정점 필요 | 필요 없음 |
| 최적 환경 | 인접 리스트로 표현된 밀집 그래프 | 간선 리스트로 표현된 희소 그래프 |
Implementation
Prim 알고리즘은 Heap 기반, 인접행렬 기반 총 두가지 방법으로 구현할 수 있습니다. 아래 코드는 Heap 기반 기준입니다.
import heapq
def prim(mx_node, edges):
graph = [[] for _ in range(mx_node + 1)]
for v1, v2, c in edges:
graph[v1].append([v2, c])
graph[v2].append([v1, c])
mst, costs = [], 0
pq, check = [[0, 3, -1]], [0] * (mx_node + 1)
while pq:
c, n, pn = heapq.heappop(pq) # 비용, 현재 노드, 이전 노드
if check[n]:
continue
check[n] = 1
costs += c
if pn != -1:
mst.append([pn, n, c])
for nn, nc in graph[n]:
if not check[nn]:
heapq.heappush(pq, [nc, nn, n])
return mst, costs
print(prim(
7,
[[1, 2, 3],
[1, 3, 1],
[1, 4, 4],
[2, 3, 1],
[2, 5, 6],
[3, 4, 5],
[3, 5, 2],
[4, 5, 7]]
)) 결과는 아래와 같이 나오게 됩니다.
# output (MST 를 구성하는 간선들, MST의 비용)
[[3, 1, 1], [3, 2, 1], [3, 5, 2], [1, 4, 4]], 8Time Complex
Heap 기반 Prim 알고리즘의 시간복잡도는 O(E LogV) 입니다. Prim 내 연산들에 대한 시간복잡도는 아래와 같습니다.
| 단계 | 설명 | 시간 복잡도 |
|---|---|---|
| 초기화 | 시작 정점을 우선순위 큐에 삽입 | O(1) |
| 간선 선택 및 큐 갱신 | 우선순위 큐에서 최소 가중치 간선 선택 및 인접 간선 추가 | O(E log V) |
인접행렬 기반 Prim 알고리즘의 시간복잡도는 O(V²) 입니다. Prim 내 연산들에 대한 시간복잡도는 아래와 같습니다.
| 단계 | 설명 | 시간 복잡도 |
|---|---|---|
| 초기화 | 시작 정점 선정 및 방문 배열 초기화 | O(V) |
| 정점 순회 및 최소 간선 탐색 | 매 단계마다 현재 MST에 연결된 정점과 인접한 정점 중 최소 가중치 간선 탐색 | O(V²) |