Selection Sort
선택 정렬(Selection Sort) 은 제자리 정렬(In-Place Sorting) 알고리즘 중 하나입니다. 선택 정렬은 각 라운드(Round)마다 배열에서 최솟값 혹은 최댓값 을 찾아 왼쪽으로 정렬하는 형태로 동작합니다.
제자리 정렬(In-Place Sorting) 알고리즘
제자리 정렬은 추가적인 메모리 공간을 거의 사용하지 않고 원래 주어진 배열 또는 리스트 내에서 요소들을 정렬하는 알고리즘을 말합니다.
Round(라운드)
Round(라운드) 는 반복적인 정렬 알고리즘에서 한 번의 주요 연산이 진행되는 단계를 의미합니다. 즉, 한 Round 마다 배열의 특정 부분 혹은 일부가 정렬되게 됩니다. N 개의 원소를 정렬하려면 N - 1 개의 Round 가 필요합니다. 라운드는 주로 선택 정렬, 버블 정렬, 삽입 정렬 같은 알고리즘에서 사용됩니다.
Process
길이가 N 인 배열을 오름차순 정렬을 한다고 가정한다면 총 N - 1 라운드가 진행되며, 각 라운드에서는 다음과 같은 과정이 이루어집니다.
- Round 1 : 시작 인덱스
idx 0값과idx 1 ~ (N - 1)값들을 차례대로 비교하여가장 작은 값을 갖는 idx 를 찾아 시작 idx 와 Swap합니다. - Round 2 : 시작 인덱스
idx 1값과idx 2 ~ (N - 1)값들을 차례대로 비교하여가장 작은 값을 갖는 idx 를 찾아 시작 idx 와 Swap합니다. - Round 3 : 시작 인덱스
idx 2값과idx 3 ~ (N - 1)값들을 차례대로 비교하여가장 작은 값을 갖는 idx 를 찾아 시작 idx 와 Swap합니다. - …
- Round N - 1 : 시작 인덱스
idx N - 2값과idx (N - 1) ~ (N - 1)값들을 차례대로 비교하여가장 작은 값을 갖는 idx 를 찾아 시작 idx 와 Swap합니다.
말로면 설명하면 이해하기 어려울 수 있기 때문에, 길이가 5인 1차원 배열 [17,14,13,15,16] 을 오름차순하는 예시를 한번 살펴보겠습니다. 길이가 5 인 배열이니 총 4 개의 Round 가 동작하게 됩니다.
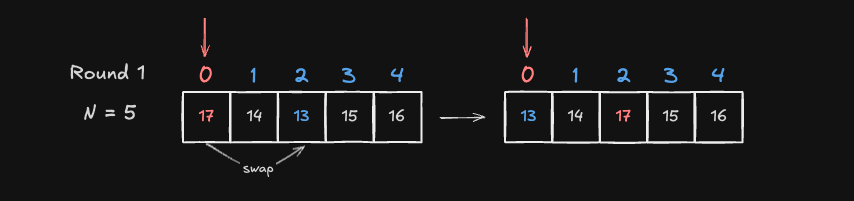
Round 1
Round 1은 시작 인덱스가 Index 0 인 17 과 Index 1 ~ 4 값들을 차례대로 비교하여 최소값 13(Index 2)과 Swap하여 배열을 정렬합니다.
- 정렬된 상태:
[13, 14, 17, 15, 16]
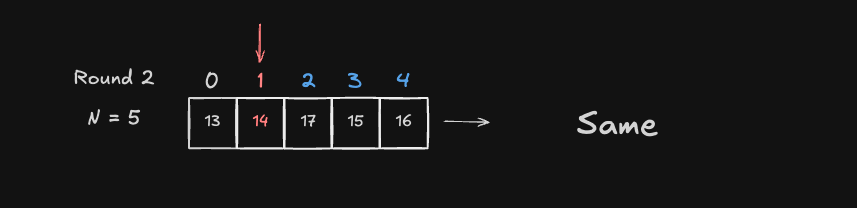
Round 2
Round 2 은 시작 인덱스가 Index 1 인 14 과 Index 2 ~ 4 값들을 차례대로 비교합니다. 하지만, 최소값이 시작 인덱스와 동일합니다. 따라서 해당 Round 에서는 Swap 하지 않습니다.
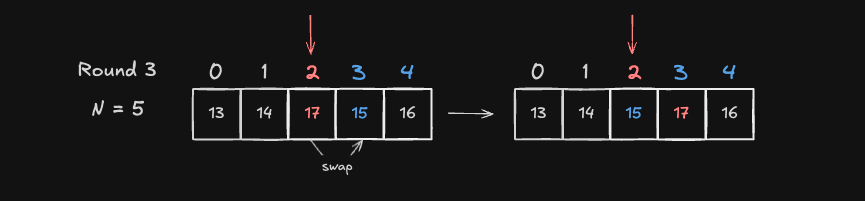
Round 3
Round 3 은 시작 인덱스가 Index 2 인 17 과 Index 3 ~ 4 값들을 차례대로 비교하여 최소값 15(Index 3)과 Swap하여 배열을 정렬합니다.
- 정렬된 상태:
[13, 14, 15, 17, 16]
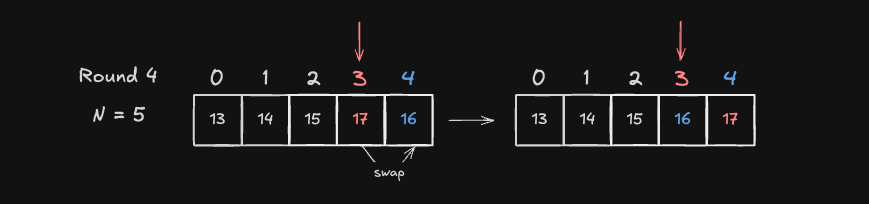
Round 4
Round 4 는 시작 인덱스가 Index 3 인 17 과 Index 4 ~ 4 값들을 차례대로 비교하여 최소값 16(Index 4)와 Swap하여 배열을 정렬합니다.
- 정렬된 상태:
[13, 14, 15, 16, 17]
End
4개의 Round 가 모두 끝났으니 정렬 과정이 종료됩니다.

Code
오름차순을 기준으로 한 최적화 전 코드입니다. curr가 배열의 각 인덱스를 돌며, curr 이후의 값들 중에서 가장 작은 값을 찾고, 이를 curr 위치와 교환합니다.
교환이 항상 수행되므로, curr 위치와 최소값이 같더라도 교환이 이루어집니다. 즉, 이미 curr 위치에 값이 올바르게 위치한 경우에도 불필요한 교환이 발생합니다.
def selection_sort(arr):
""" 최적화 전 """
N = len(arr)
for curr in range(N - 1): # 총 N - 1 번의 라운드 수행. (각 라운드는 현재 index 를 의미합니다.)
mn_idx = curr # 현재 라운드에서 최소값을 찾을 index 초기화
for idx in range(curr + 1, N): # 현재 index 이후의 값들 탐색
if arr[idx] < arr[mn_idx]:
mn_idx = idx
arr[mn_idx], arr[curr] = arr[curr], arr[mn_idx] # Swap 을 수행합니다.
return arr위의 코드를 기반으로 한 최적화 후 코드입니다. 딱 한부분만 달라졌습니다.
- 이전에는
curr와mn_idx가 동일하더라도무조건 교환을 수행했다면 - 이후에는
curr와mn_idx가다를 때만 교환을 수행합니다. 이로 인해 불필요한 연산(교환)을 줄일 수 있습니다.
def selection_sort(arr):
""" 최적화 후 """
N = len(arr)
for curr in range(N - 1):
mn_idx = curr
for idx in range(curr + 1, N):
if arr[idx] < arr[mn_idx]:
mn_idx = idx
if curr != mn_idx: # 현재 index 와 최소값 index 가 다르면 Swap 을 수행합니다.
arr[mn_idx], arr[curr] = arr[curr], arr[mn_idx]
return arr장단점
장점
- 구현이 간단하고 직관적입니다.
- 제자리 정렬 (In-Place Sorting) 알고리즘 중 하나이기 때문에 추가적인 메모리 공간을 거의 사용하지 않습니다.
- 정렬되지 않은 데이터셋 크기에 상관없이 최선, 평균, 최악 모두
O(N²)의 일정한 시간복잡도를 갖습니다. - 삽입 정렬이나 버블 정렬보다
데이터 교환 횟수가 적어메모리 쓰기 작업이 적어 효율적입니다.
단점
- 최선, 평균, 최악 모두
O(N²)로 일정한 시간복잡도를 갖지만,O(N²)자체가 비효율적입니다. - 동일한 값을 가지는 원소들의 상대적인 순서가 변경될 수 있는
불안정 정렬(Unstable Sort)입니다. - 이미 정렬된 경우에도 동일한 연산을 수행하기 때문에 비효율적입니다.