Heap
Heap 은 우선순위 큐(Priority Queue)를 효율적으로 구현하기 위해 만들어진 완전 이진 트리(Complete Binary Tree) 형태의 자료구조 입니다. Heap 을 사용하면 아래와 같은 장점이 있습니다.
- 여러 개의 값들 중에서 최댓값 혹은 최솟값을 빠르게 찾을 수 있습니다.
- 이진 탐색 트리(Binary Search Tree) 와는 달리 중복 값을 허용하는 것이 특징입니다.
느슨한 정렬 (반정렬)
Heap 은 완전히 정렬된 상태는 아니지만 정렬이 안된 것도 아닙니다. 이러한 상태를 느슨한 정렬 또는 반정렬 상태라고 합니다.
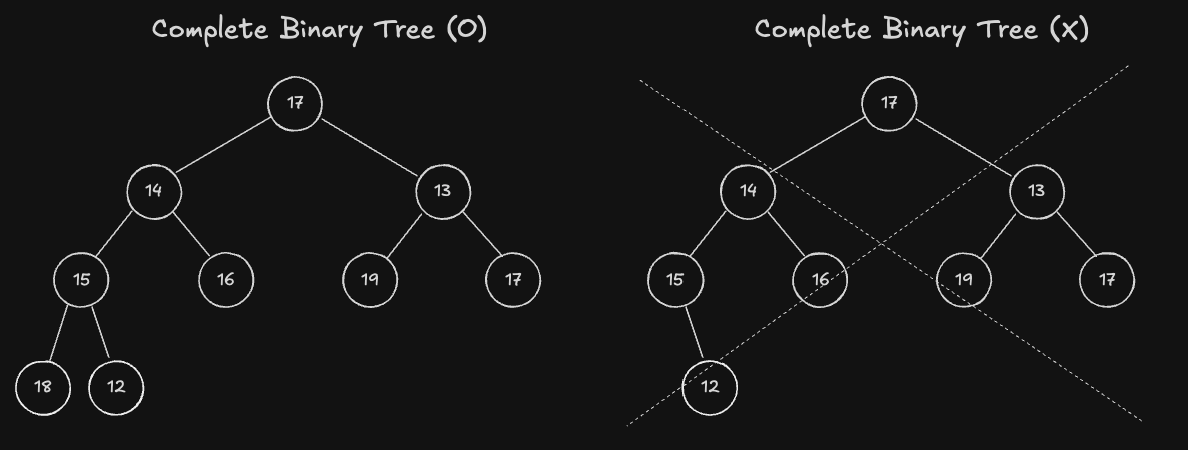
Complete Binary Tree
완전 이진 트리(Complete Binary Tree) 는 다음과 같은 조건을 만족하는 이진 트리(Binary Tree) 를 의미합니다.
- 마지막 Level 을 제외하고 모든 Node 가 채워져있어야 합니다. (마지막 Level 의 Node 는 다 채워져 있을 수도 있고 아닐수도 있습니다.)
- 트리를 구성하는 Node 는 왼쪽에서 오른쪽 방향으로 채워져야 합니다. (특정 Node 가 오른쪽 자식을 갖고 있다면, 왼쪽 자식도 갖고 있어야 합니다.)
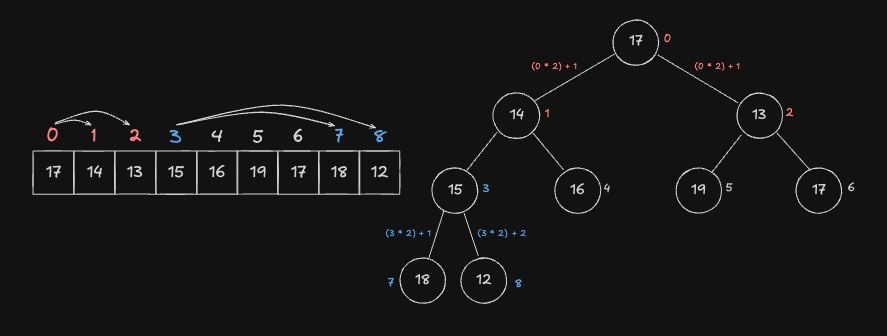
배열로 표현한 완전 이진 트리
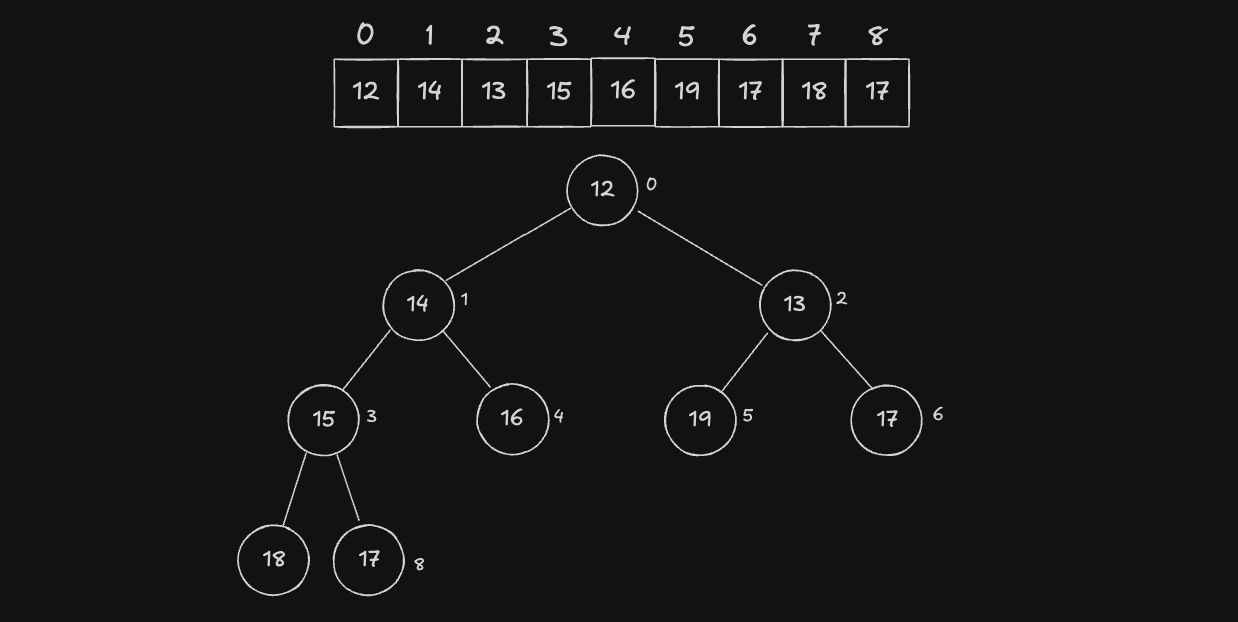
완전 이진 트리는 1차원 배열로 표현할 수 있습니다. 현재 Node 가 idx 라고 가정했을 때, 자식 노드를 알 수 있는 계산식은 다음과 같습니다.
| 현재 Node 번호 | 부모 | 왼쪽 Child | 오른쪽 Child | |
|---|---|---|---|---|
| Index 0 시작 배열 | index | (index - 1) // 2 | index * 2 + 1 | index * 2 + 2 |
| Index 1 시작 배열 | index | index // 2 | index * 2 | index * 2 + 1 |
아래 그림은 index 가 0 부터 시작하는 배열을 기준으로 완전 이진 트리를 나타낸 것입니다.
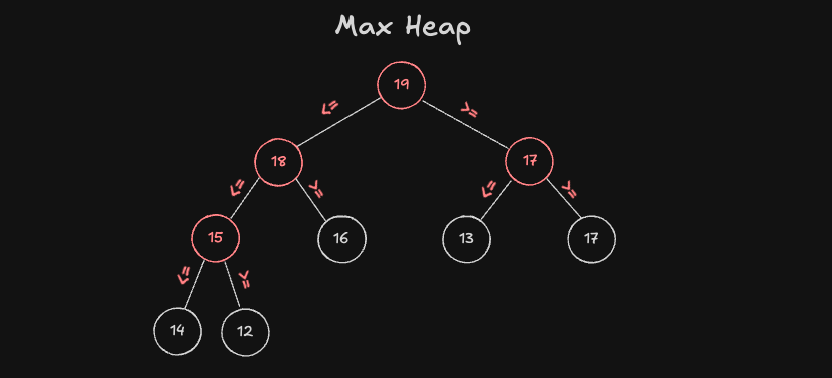
Heap 종류
Heap 에는 최대 힙 그리고 최소 힙 두가지가 존재합니다.
최대 힙
최대 힙은 이진 트리를 구성하는 모든 Node 가 자식노드의 키 값보다 항상 크거나 같은 것을 의미합니다.
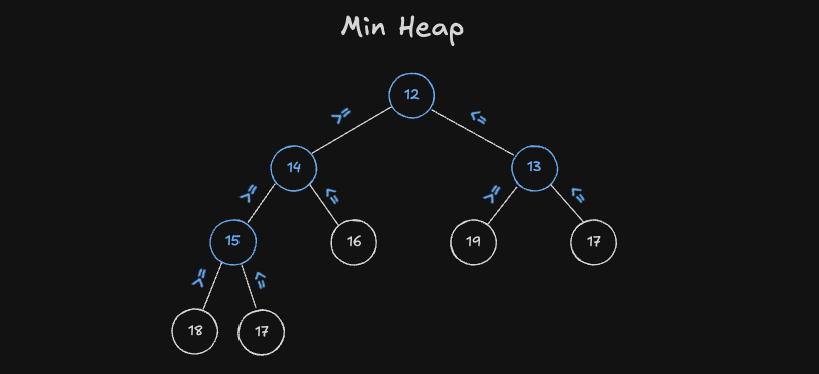
최소 힙
최소 힙은 이진 트리를 구성하는 모든 Node 가 자식노드의 키 값보다 항상 작거나 같은 것을 의미합니다.
Heap 연산
Heap 에서 사용되는 연산은 세가지가 있습니다.
- push : 이미 힙 구조를 가진
배열의 끝에 새로운 원소를 추가하는 연산을 말합니다. - pop : 이미 힙 구조를 가진 배열에서
가장 작거나 가장 큰 값 (index 0) 을 제거하는 연산을 말합니다. - heapfiy : 배열(완전 이진 트리)을 구성하는
특정 Node 를 Root 로 하는 SubTree 전체가 Heap 속성을 만족하도록 조정하는 과정 및 연산(매우 중요)
원소 추가 (push)
“Heap 에 Push” 한다는 것은 이미 Heap 구조를 가진 배열(완전 이진 트리) 끝에 새로운 Node 를 추가하는 것 을 의미합니다. 해당 연산은 아래와 같은 프로세스로 동작합니다. 참고로 뒤에 설명하겠지만 해당 연산은 O(Log N) 시간복잡도를 가집니다.
- Heap 구조를 가진 배열(완전 이진 트리)의 끝에 새로운 Node 를 추가합니다.
- 추가된 Node 와 Parent 를 구성하고자하는 Heap 특성(최대힙인지 최소힙인지)에 맞게 비교하여 교환합니다.
- 예제에서는 최소힙 유지가 목표이므로 추가된 Node 보다 Parent 가 크면 값을 교환합니다.
- 2번 과정을 Root 노드까지 진행하되, 특정 Node 에서 이미 최소힙을 만족한다면 멈춥니다.
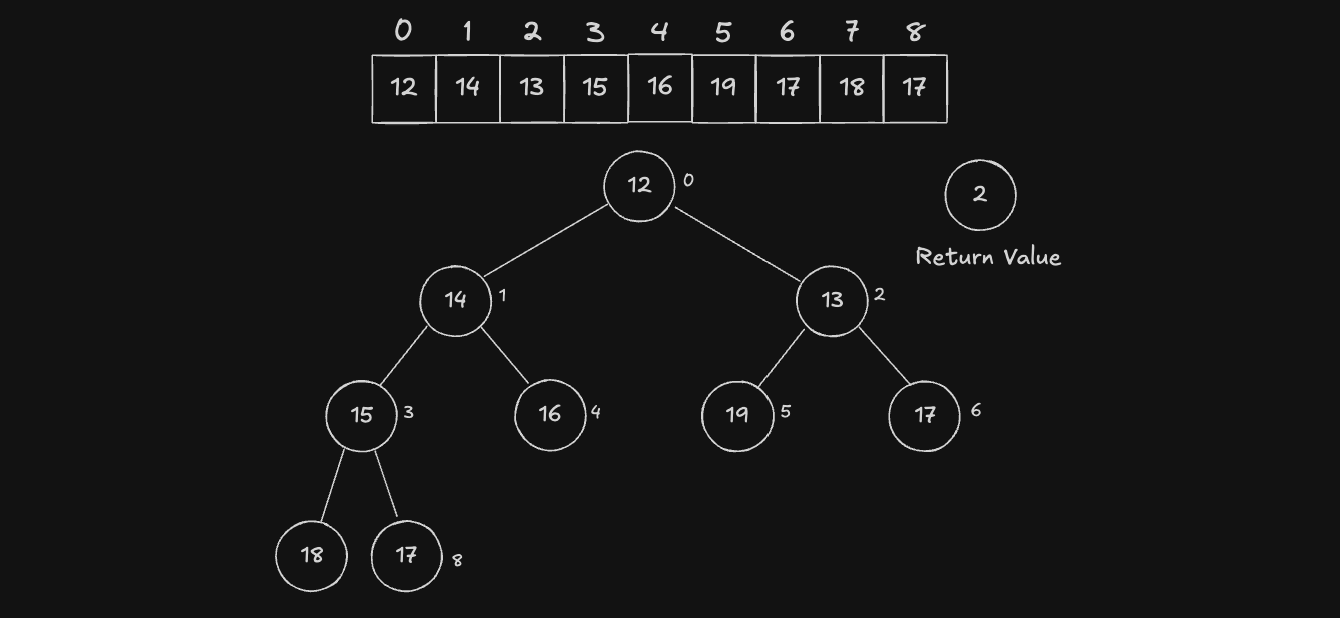
이미 최소힙 구조를 갖는 [12, 14, 13, 15, 16, 19, 17, 18, 17] 배열에 새로운 Node 인 2 를 push 하는 과정을 보겠습니다. 제일 먼저 배열의 끝에 새로운 노드 2 를 push 해줍니다.
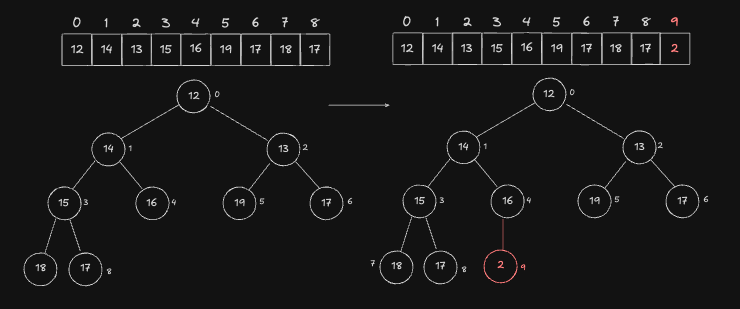
추가된 Node 와 Parent 를 비교합니다. 최소 힙 을 유지하는것이 목표이기 때문에 Parent 가 추가된 Node 보다 작으면 교환해줍니다. 따라서 Parent 인 index 4 번 Node 와 index 9 번 Node 를 교환합니다.
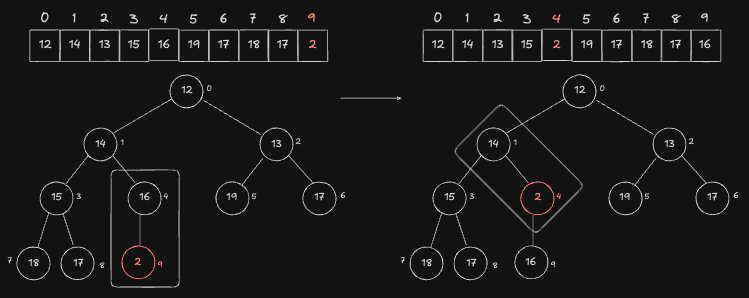
현재 Node 는 index 4번 입니다. 또한, Parent 는 index 1번 Node 입니다. 마찬가지로 Parent 가 현재 Node 보다 더 작기 때문에 이 둘을 교환합니다.
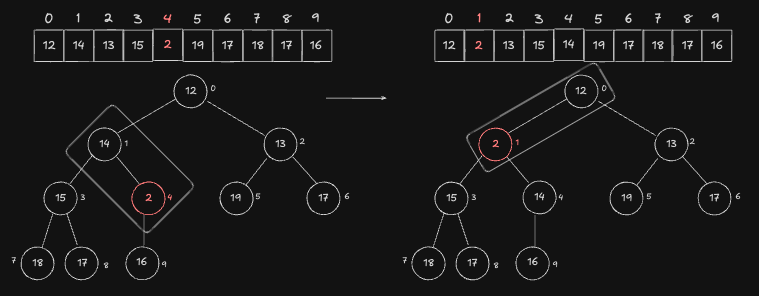
현재 Node 는 index 1번 입니다. 또한, Parent 는 index 0번 Node 입니다. 마찬가지로 Parent 가 현재 Node 보다 더 작기 때문에 이 둘을 교환합니다.

여기까지가 기존 Heap 에 새로운 Node 를 push 하는 과정입니다. 단, 위 예시에서는 Root Node 까지 교환을 마쳤기 때문에 탐색할 Node 가 없어 종료되었지만, Root Node 로 가기 전에 이미 최소 힙을 만족하는 Node 가 있었다면, 그곳에서 탐색을 종료하면 됩니다.
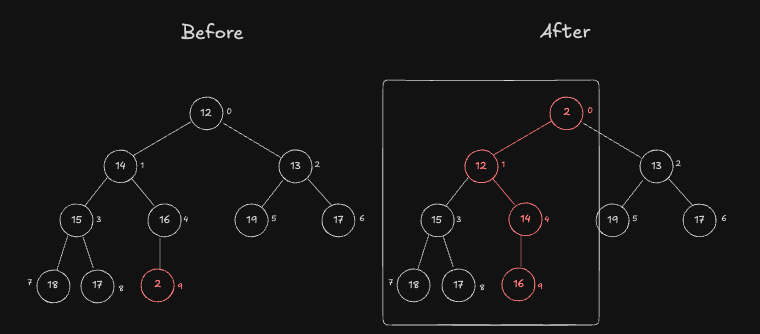
위 과정에서 중요한 것은 처음에 삽입된 경로(12,14,15,16,18,17,2)에만 영향을 받고, 반대편 SubStree(13,19,17)에는 전혀 영향을 주지 않는다는 점입니다.
- 부모와 현재 노드를 비교하면서 위로 올라가는데, 이 과정에서 Parent 와 Child 관계만 조정하지, 반대편 SubTree 는 건드리지 않습니다.
- 따라서 단일 경로 (삽입된 Node → Root Node) 만 수정하므로 다른 Subtree 는 그대로 유지됩니다.
- 오직 부모 방향으로만 조정되므로
O(Log N)시간복잡도를 가집니다.
지금까지의 과정은 아래와 같은 코드로 짤 수 있습니다.
def heappush(heap, node):
heap.append(node)
curr = len(heap) - 1 # 삽입된 Node 의 index
while curr > 0: # 현재 Node(index)가 Root(index 0) 에 도달하면 종료
parent = (curr - 1) // 2 # Parent Node 의 index
if heap[parent] > heap[curr]: # Parent 값이 현재 Node 보다 작으면 (최소힙)
heap[parent], heap[curr] = heap[curr], heap[parent] # Parent 값과 Node 값 교환
curr = parent # 추가한 Node 의 index 를 갱신
else:
break원소 제거 (pop)
“Heap 에 원소를 Pop” 한다는 것은 이미 Heap 구조를 가진 배열(완전 이진 트리)의 Root Node(index 0) 를 삭제하는 것을 의미합니다. 이전에 최소 힙을 구성했으므로 index 0 에는 가장 작은 Node 가 위치할텐데, 해당 Node 를 pop 해주는 것입니다. 해당 연산은 아래와 같은 프로세스로 동작합니다. 뒤에 설명하겠지만 해당 연산도 O(Log N) 시간복잡도를 가집니다.
- Root Node 를 삭제합니다.
- Root Node 가 있던 자리에 Heap 의 맨 마지막 Node 값을 대입시킵니다.
- Root Node(index 0) 번 Node 의 Heap 을 재구성 (Heapify) 합니다. (매우 중요)
2 라는 원소를 추가한 [2, 12, 13, 15, 14, 19, 17, 18, 17, 16] 힙에서 원소를 pop 하는 과정을 알아보겠습니다. 통상적으로 1 번 과정과 2 번과정은 다른 프로세스이지만, 코드상에서는 동시에 진행하게 됩니다.
루트 노드 삭제와 임시저장
최소힙인 index 0번 Node 와 마지막 노드인 index 9번 Node 를 교환합니다.
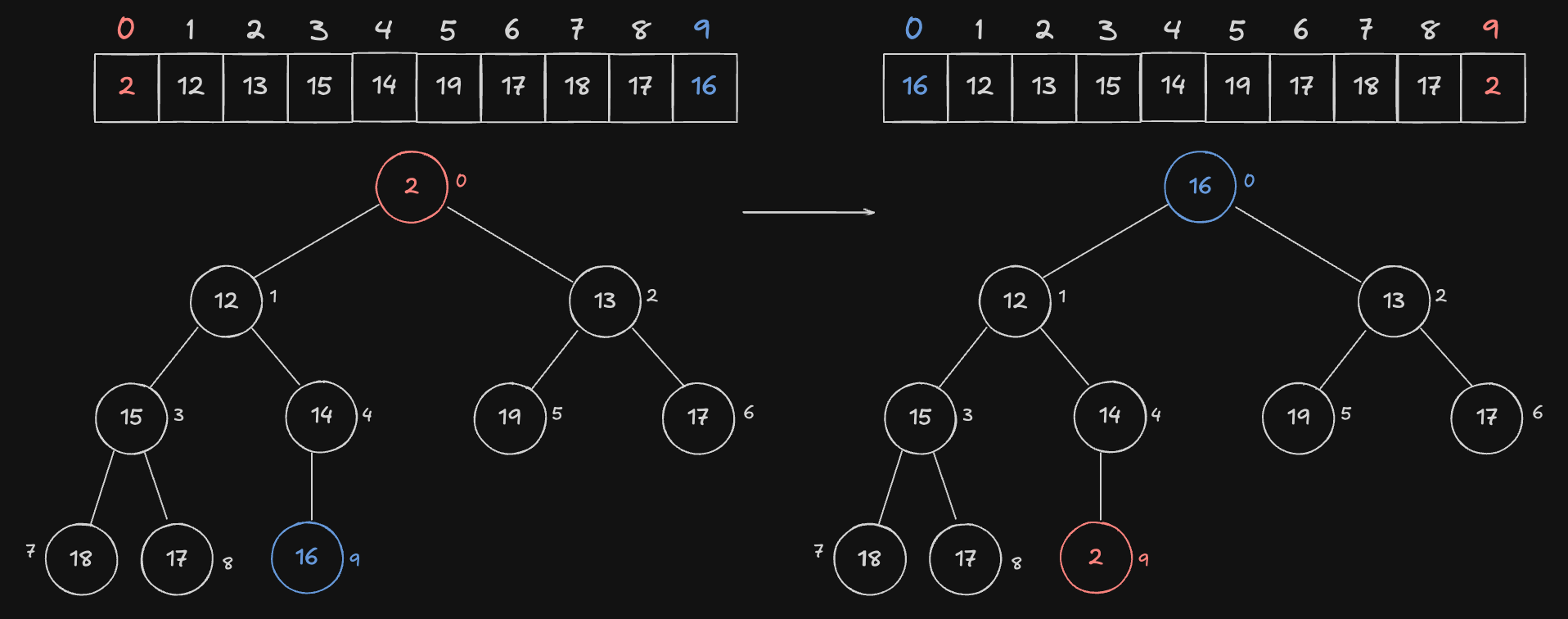
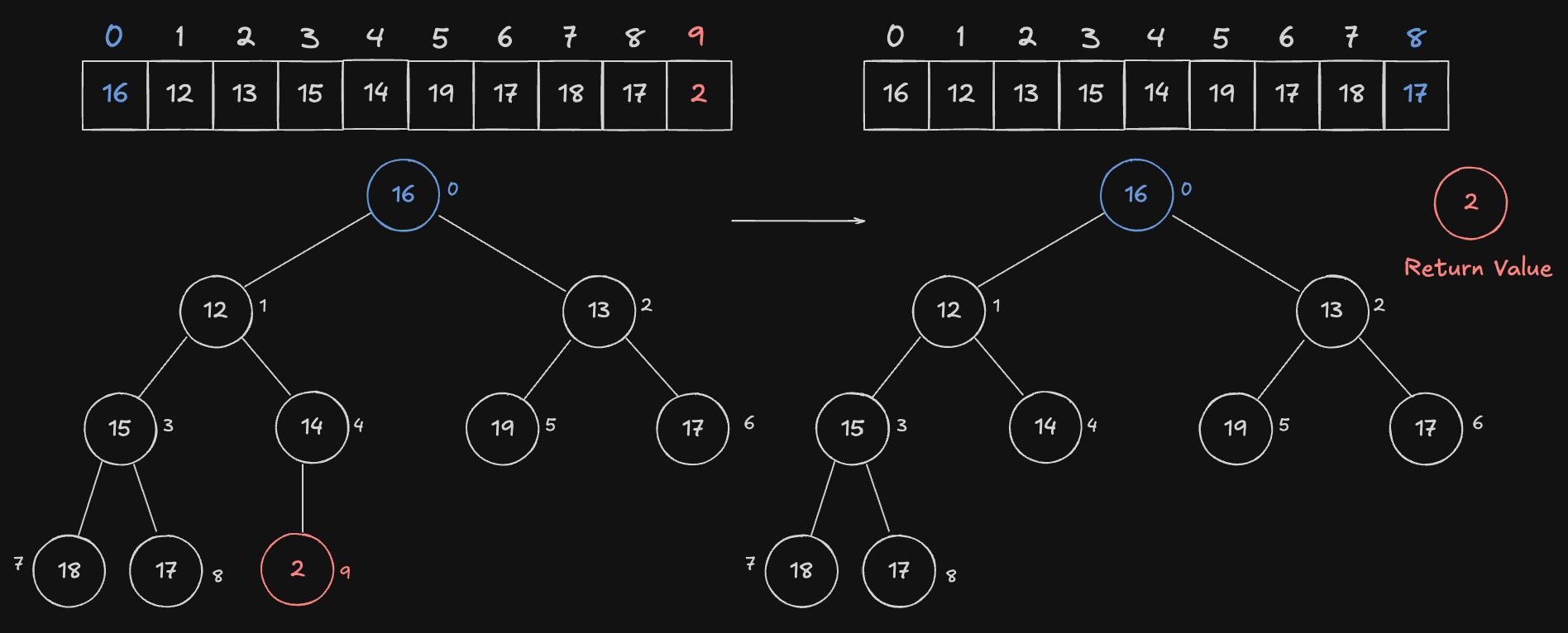
Node 를 교환했기 때문에, 최소힙 Node 는 Heap 의 맨 마지막에 위치하게 됩니다. 이제 pop 을 해주어 가장 작은 원소 를 임시저장합니다. 임시저장하는 이유는 Heap 을 재구성해야하기 때문입니다. 재구성 후 임시저장한 값을 반환해주면 됩니다.
여기까지가 1 번 과정과 2 번 과정의 끝입니다.
힙화 (heapify)
이제 Heap 을 재구성할 차례입니다. Heap 은 재구성한다는 것은 특정 Node 를 Root 로 하는 SubTree 전체가 Heap 속성을 만족하도록 조정하는 과정 이며 이것을 힙화(Heapify) 라고 합니다. Heapify 는 Heap 을 구현함에 있어 매우 중요한 내용입니다. 왜냐하면 Heap 에서 원소를 pop 하고 Heap 을 재구성하는데도 사용되고, Heap 구조가 깨져있는 일반적인 1차원 배열을 한번에 Heap 구조로 만드는데도 사용되기 때문입니다. 참고로 특정 Node 에서 시작하는 Heapify 에 걸리는 시간 복잡도는 O(Log N) 입니다.
Heapify 는 다음과 같은 프로세스로 진행되게 됩니다.
- 초기 Root 로 지정할 특정 Node(index)를 정합니다. (Heap 을 재구성하고자하는 SubTree 의 Root Node)
Root Node(현재 Node) 값과Child Node 의 값을 힙의 특성(예시에서는 최소힙)에 따라 비교합니다.- Root Node(현재 Node) 가 가장 작아 최소 힙 속성을 만족한다면
- 탐색을 종료합니다.
- 그렇지 않다면 값이 가장 작은 Min Node 와 Root Node 값을 Swap 합니다.
- 현재 노드인 Root Node 를 Min Node(index) 로 재지정하고, Root Node(현재 Node) 의 Child Node 가 없을때까지
2번 과정을 반복합니다.
- Root Node(현재 Node) 가 가장 작아 최소 힙 속성을 만족한다면
헷갈리지 말자
“특정 Node 와 Child1, Child2 간의 Heap 을 재구성한다” 라는 말도 Heapify 의 과정 중 하나이기 때문에 해당 표현도 옳지만, 보다 정확한 표현은 특정 Node 를 Root 로 하는 SubTree 전체가 Heap 속성을 만족하도록 조정하는 과정 입니다.
설명은 충분하니 이제 다시 본론으로 돌아와 Heap 을 재구성해봅시다. 맨 처음 최소힙(index 0) 과 마지막 원소(index 9 = 지금은 사라짐) 를 교환했기 때문에, index 0 번 Node 의 서브트리들의 Heap 속성이 깨졌을 가능성이 매우 높습니다. 따라서 0 번 index 를 Root Node 로 지정합니다.
현재 노드인 Root Node(index 0) 와 Child Node1(index 1), Child Node2(index 2) 값을 비교합니다. 최소 힙 속성(현재 노드인 Root Node 가 가장 작지 않음) 을 만족시키지 못하기 때문에 현재 노드인 Root Node 와 가장 작은 값을 갖는 Child Node1 의 값을 swap 합니다. 또한, Root Node 를 교환한 index 1번 Node 로 재지정 합니다.
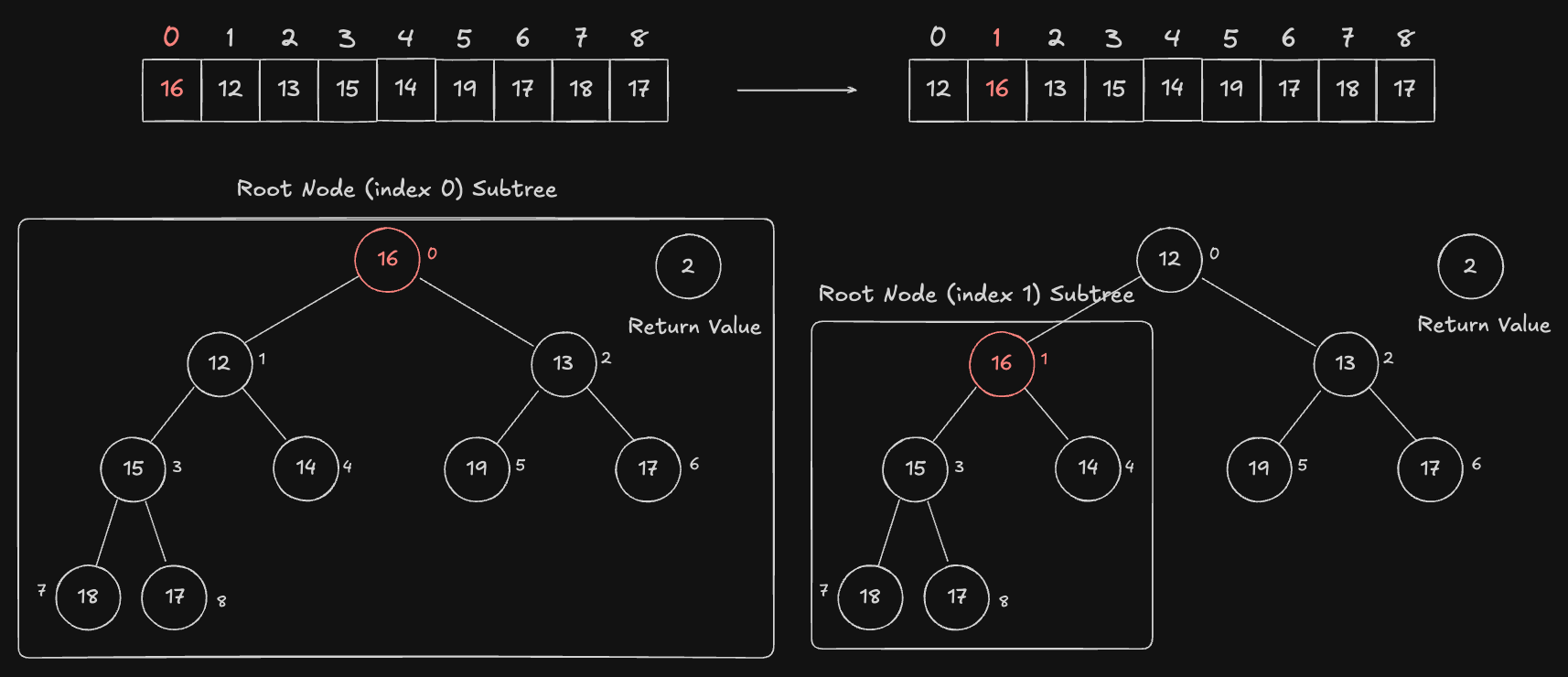
현재 노드인 Root Node(index 1) 와 Child Node1(index 3), Child Node2(index 4) 값을 비교합니다. 마찬가지로 최소 힙 속성(현재 노드인 Root Node 가 가장 작지 않음) 을 만족시키지 못하기 때문에 현재 노드인 Root Node 와 가장 작은 값을 갖는 Child Node2 의 값을 swap 합니다. 또한, Root Node 를 교환한 index 4번 Node 로 재지정 합니다.
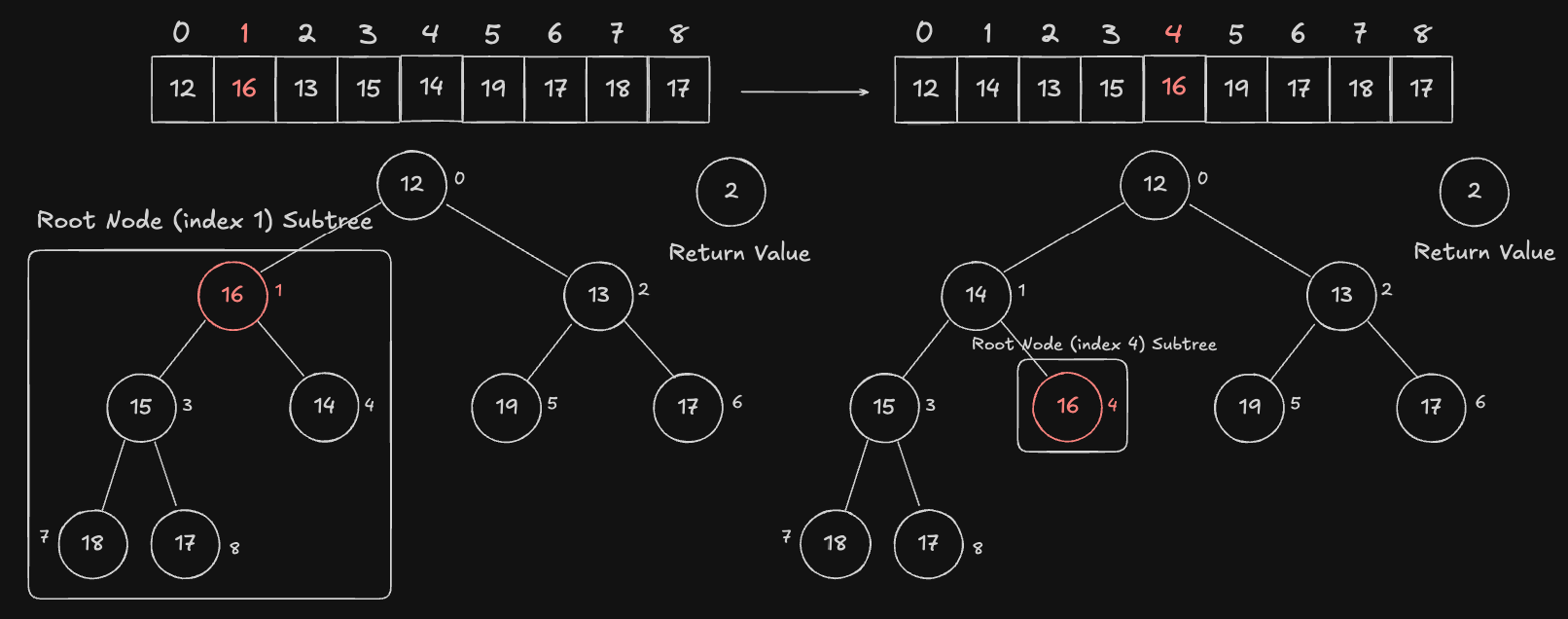
하지만 현재 노드인 Root Node(index 4) 는 Child Node 가 없습니다. 따라서 탐색을 종료합니다. 여기까지가 Heapfiy 의 흐름입니다.
Code
Heapify 는 재귀와 while 문 두가지 방법으로 구현할 수 있습니다. 하지만 Python 에서는 기본 recursion limit 이 걸려있기 때문에 while 문을 사용하는것이 메모리상 훨씬 더 안정적입니다.
while 문으로 구현
def _heapify(heap, root, length):
while root * 2 + 1 < length:
curr = root
child1, child2 = curr * 2 + 1, curr * 2 + 2
if child1 < length and heap[child1] < heap[curr]: # Child1 과 비교
curr = child1
if child2 < length and heap[child2] < heap[curr]: # Child2 와 비교
curr = child2
if root == curr:
break
heap[root], heap[curr] = heap[curr], heap[root]
root = curr재귀로 구현
def _heapify(heap, root, length):
curr = root
if curr * 2 + 1 >= length:
return
child1, child2 = root * 2 + 1, root * 2 + 2
if child1 < length and heap[child1] < heap[curr]: # Child1 과 비교
curr = child1
if child2 < length and heap[child2] < heap[curr]: # Child2 와 비교
curr = child2
if curr != root:
heap[root], heap[curr] = heap[curr], heap[root]
_heapify(heap, curr, length)임시저장한 값을 반환
Heap 을 재구성했으니, 임시저장했던 원소를 이제 Return 해주면 Heap 에서 원소를 제거하는 pop() 연산이 종료되게 됩니다.
Code
Heap 에서 원소를 pop 하는 과정인 아래 프로세스를 구현한 코드입니다.
def heappop(heap):
if not heap:
raise IndexError("pop from empty heap")
heap[0], heap[-1] = heap[-1], heap[0] # Heap 의 Root 와 맨 마지막을 Swap
removed = heap.pop() # pop 하여 가장 작은 값을 임시저장
length = len(heap)
root = 0 # Root Node 를 명시적으로 표현
_heapify(heap, root, length) # Root Node(index 0) 로부터 Heap 재구성
return removed배열을 한번에 Heap 구축
지금까지 Heap 에 원소를 push 하는 연산과 원소를 pop 하는 연산을 알아보았습니다. 하지만 이 두개의 연산은 모두 이미 Heap 의 속성을 만족하는 배열 에 연산을 취한다는 공통적인 선행조건이 있었습니다. 물론 처음부터 빈 배열에서 시작해 원소들을 하나씩 push 해가면 Heap 속성을 유지하면서 Heap 을 확장시킬 수 있습니다. 그렇다면 Heap 속성을 만족하지 않는 배열을 한번에 Heap 속성을 만족하도록 만들 수 없을까요? 물론 해당 질문을 하는것 자체가 방법이 있기 때문이겠죠? 지금 그 설명을 하고자 합니다.
아래의 완전 이진트리를 예로 들어보겠습니다. 방법은 매우 간단합니다. index 0 부터 시작하는 길이가 N 인 배열이 있다면, index 가 (N // 2) - 1 번째 Node 부터 0 번 index 순으로 heapify 과정을 수행하면 됩니다.
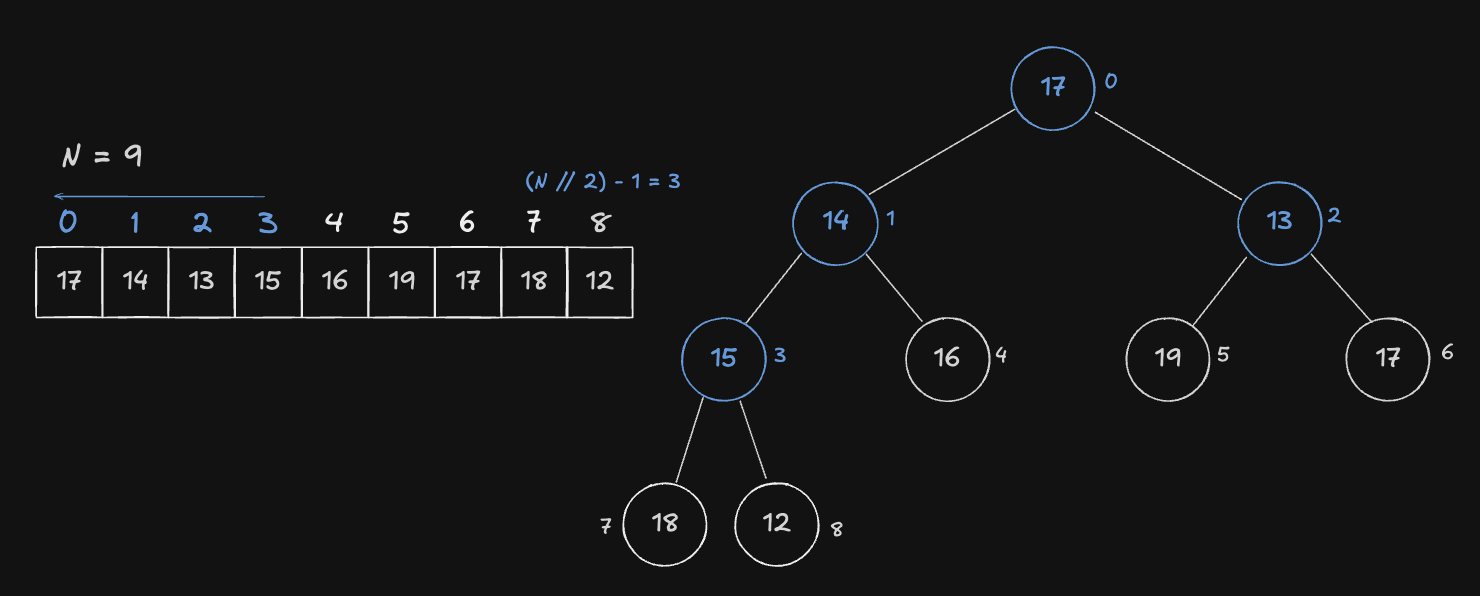
왜 (N // 2) - 1 번째 Node 부터 시작하나요?
Child Node 가 없으면 이미 Heap 특성을 만족하여 아무런 동작도 하지 않기 때문입니다. 따라서 배열(완전 이진 트리) 에서 가장 마지막 Node 의 Parent 인 (N // 2) - 1 인덱스부터 Heap 구축을 시작하는 것입니다. (배열의 가장 중간 노드)
왜 Index 가 높은 Node 부터 시작하나요? (Bottom-Up)
Heapify는 부모 노드에서 자식 노드로 내려가면서 값을 조정하는 과정입니다. 즉, 특정 노드를 Root로 하는 Subtree를 Heap 구조로 만들 때, 부모 → 자식 방향으로 진행되며, 자식 노드는 그 자체로 Heap 특성을 만족해야 합니다.
하지만 만약 Index가 낮은 순서(0 → (N//2)-1)로 Heapify 하면, 부모 노드를 먼저 처리하는데, 그 아래 자식들이 아직 정렬되지 않은 상태이므로, 부모를 Heapify해도 이미 깨진 자식 트리 때문에 완전한 Heap이 되지 않습니다.
결과적으로, 값이 가장 작은(또는 가장 큰) 노드가 Root로 올라올 수 없게 되어 Heapify가 제대로 동작하지 않게 됩니다. 따라서 Index가 높은 노드부터(Leaf 에서 Root 로) 처리하는 Bottom-Up 방식 으로 진행해야 합니다.
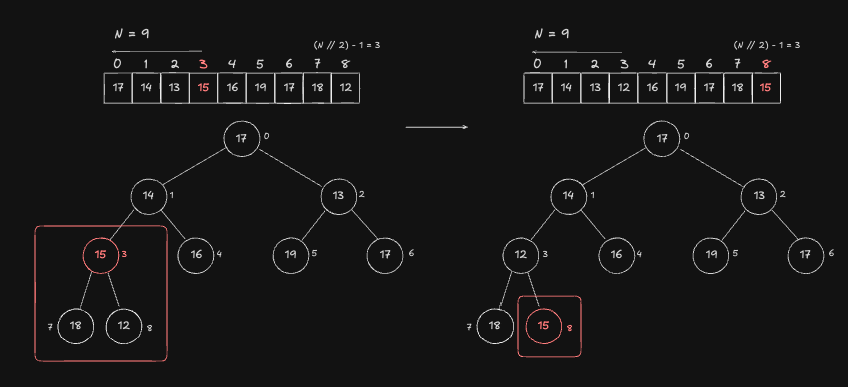
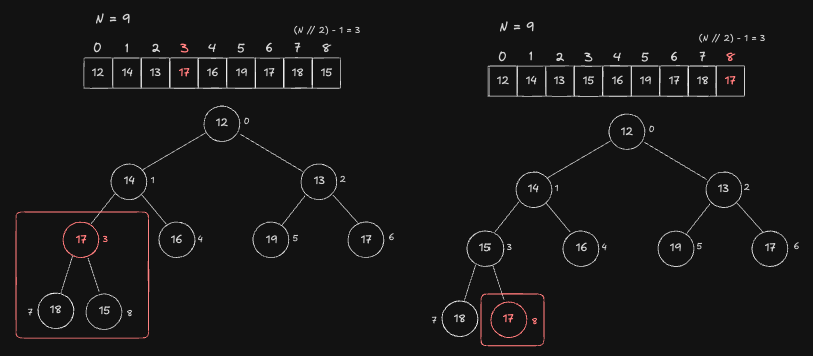
Index 3 Node
시작은 Index 3 번 Node 부터 출발합니다. 각 Node 를 Root 로 하는 모든 Subtree 를 Heap 특성을 만족하도록 조정하는 Heapify 연산은 앞서 매우 구체적으로 설명했으므로 전체적인 흐름만 보도록 하겠습니다.
- Index 3 번 Node 의 Child 인 8 번 Node 과 값을 Swap 하여 Heap 특성을 만족시킵니다.
- Index 8 번 Node 는 Child 가 없는 Leaf 이기 때문에 탐색을 종료하게 됩니다.
Index 2 Node
다음 순서인 Index 2 번 Node 입니다.
2번 Node 는 Child 인 5,6 번 Node 보다 작기 때문에 이미 Heap 특성을 만족합니다. 따라서 값을 Swap 하지 않고 탐색을 종료합니다.
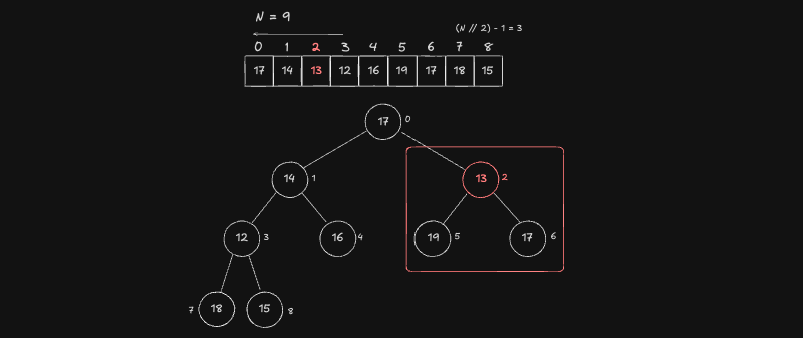
Index 1 Node
다음 순서인 Index 1 번 Node 입니다.
- 1번 Node 의 Child 인 3,4번 중 3번이 제일 작기때문에 1번 Node 와 3번 Node 의 값을 Swap 하여 Heap 특성을 만족시켜줍니다.
- 3번 Node 와 Child 인 7,8번 중 자기 자신(3번) 이 제일 작기 때문에 이미 Heap 특성을 만족합니다. 따라서 탐색을 종료합니다.
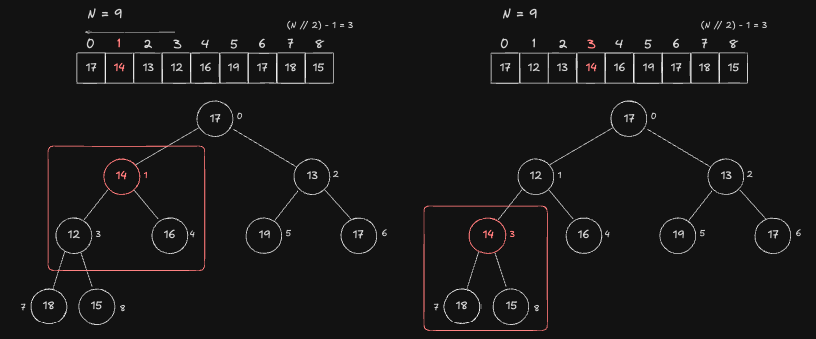
Index 0 Node
마지막 Root Node 인 1번 Index 노드입니다. 0번 Node 와 Child 중 하나인 1번 노드와 값을 Swap 하여 Heap 특성을 만족시킵니다.
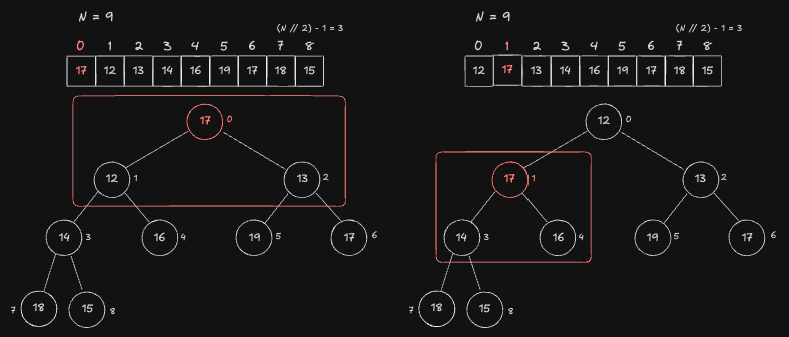
1번 Node 와 Child 노드 중 하나인 3번 노드와 값을 Swap 하여 Heap 특성을 만족시킵니다.
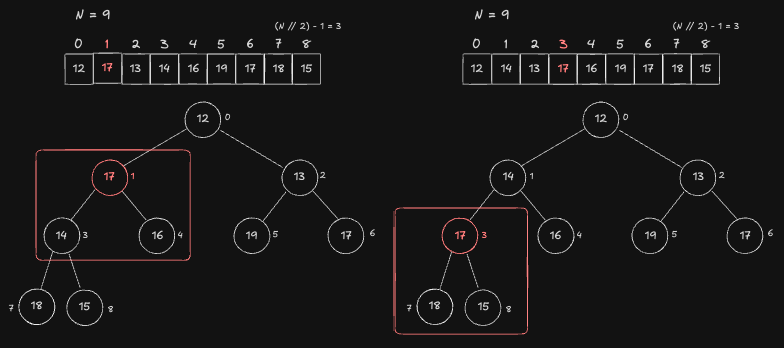
3번 Node 와 Child 노드 중 하나인 8번 Node 와 값을 Swap 하여 Heap 특성을 만족시킵니다. 8번 Node 는 Child 가 없는 Leaf 이기 때문에 탐색을 종료합니다.
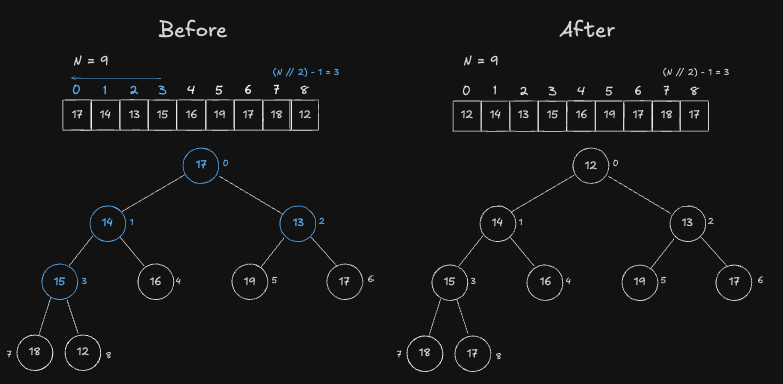
Result
여기까지 1차원 배열을 한번에 Heap 구조로 변경시키는 과정을 알아보았습니다. After 그림을 보면 모든 Node 가 Heap 특성을 만족하는 것을 보실 수 있습니다. 1차원 배열을 한번에 Heap 구조로 변경시키는 과정에 드는 시간복잡도는 O(N) 입니다. 그 내용은 해당 링크에서 확인하실 수 있습니다.
일반적으로 Heapify를 O(Log N)으로 보면 전체 N개의 노드에 대해 O(N log N)으로 보일 수도 있지만, 실제로는 최적화로 인해 O(N)으로 동작합니다.
Code
해당 과정은 아래와 같이 Python 으로 작성할 수 있습니다.
def make_min_heap(heap): # heapq 라이브러리에서는 heapfiy 이름을 사용합니다.
length = len(heap)
for i in range(length // 2 - 1, -1, -1):
_heapify(heap, i, length)전체 Code
현재까지 사용된 코드 조각들을 모두 조합하면 아래와 같습니다. 실제로 Python heapq 라이브러리와 비교해보면 결과가 완벽히 같은 것을 확인하실 수 있습니다.
import heapq
def _heapify(heap, root, length):
while root * 2 + 1 < length:
curr = root
child1, child2 = curr * 2 + 1, curr * 2 + 2
if child1 < length and heap[child1] < heap[curr]:
curr = child1
if child2 < length and heap[child2] < heap[curr]:
curr = child2
if root == curr:
break
heap[root], heap[curr] = heap[curr], heap[root]
root = curr
def heappush(heap, node):
heap.append(node)
curr = len(heap) - 1
while curr > 0:
parent = (curr - 1) // 2
if heap[parent] > heap[curr]:
heap[parent], heap[curr] = heap[curr], heap[parent]
curr = parent
else:
break
def heappop(heap):
if not heap:
raise IndexError("pop from empty heap")
heap[0], heap[-1] = heap[-1], heap[0]
removed = heap.pop()
length = len(heap)
root = 0
_heapify(heap, root, length)
return removed
def make_min_heap(heap):
length = len(heap)
for i in range(length // 2 - 1, -1, -1):
_heapify(heap, i, length)
# pq = [12, 14, 13, 15, 16, 19, 17, 18, 17]
pq1 = [17, 14, 13, 15, 16, 19, 17, 18, 12]
pq2 = [17, 14, 13, 15, 16, 19, 17, 18, 12]
# heapq 라이브러리
heapq.heapify(pq1)
heapq.heappush(pq1, 2)
heapq.heappush(pq1, 5)
heapq.heappop(pq1)
heapq.heappush(pq1, 20)
heapq.heappop(pq1)
heapq.heappush(pq1, 11)
heapq.heappop(pq1)
print(pq1)
# 구현한 것
make_min_heap(pq2) # heapq.heapfiy() 와 동일
heappush(pq2, 2)
heappush(pq2, 5)
heappop(pq2)
heappush(pq2, 20)
heappop(pq2)
heappush(pq2, 11)
heappop(pq2)
print(pq2)Summary
- Heap 우선순위 큐(Priority Queue)를 효율적으로 구현하기 위해 만들어진 완전 이진 트리(Complete Binary Tree) 형태의 자료구조
- heapify 는 특정 Node 를 Root 로 하는 Subtree 전체가 힙 속성을 만족하도록 조정하는 과정
- push 연산에 드는 시간
O(Log N) - pop 연산에 드는 시간
O(Log N) - 배열을 한번에 Heap 구조로 만드는데 드는 시간
O(N)