Redis
Redis 는 Remote Dictionary Server 의 약자이며 다수의 서버를 사용하는 분상환경의 서버가 공통으로 사용할 수 있는 key: value 형태의 HashTable 구조라고 보면 된다.
Redis 의 특징
- Redis 는 C 언어로 작성된 Open Source In-Memory Data Store 이다. 말 그대로 In-Memory 이기 때문에 백업 데이터와 Snapshot 을 제외한 데이터가 모두
RAM(Random Access Memory) 에 저장된다. 이 뜻은 휘발성 데이터이지만 데이터의 접근 속도가 매우 빠르다 - 휘발성 데이터이지만
RDB(Redis Database) +AOF(Append Only File) 라는 옵션을 통해 데이터를영속적(Persistence) 으로 관리할 수 있다. - Redis 는
Single Thread기반으로 모든 작업을 처리하기 때문에, 애플리케이션에서 발생할 수 있는 동시성문제를 조금이나마 해결할 수 있다. - 다중 모드에 데이터를 분산저장하여 안정성과 고가용성을 제공할 수 있는
ClusterMode를 지원한다. Pub/Sub같은 기술이 자체적으로 구현되어 있기 때문에 때문에 채팅, 알림과 같은 실시간 통신이 필요한 애플리케이션을 보다 쉽게 개발할 수 있다.
Redis 장점
- 모든 데이터를 RAM 에 저장하기 때문에
매우 빠른 Read/Write 속도를 보장한다. 다양한 DataType 을 지원하기 때문에 다양한 기능을 구현할 수 있다.- 다양한 언어에서 Redis Client 를 지원한다.
Redis 사용 사례
- 임시 비밀번호 (OTP), 세션(Session) 과 같은 임시데이터를 Redis 에
Caching하여 사용하는 경우가 많다. - 서버에서 특정 API 에 대한 요청 회수를 제한하기 위해 Redis 의
Rate Limiter를 사용할 수 있다. - Redis 의 Lists 나 Streams 같은 데이터타입을 활용하여
Message Queue를 구현하여 다양한 서비스간의 Coupling 을 줄일 수 있다. - 순위표, 반경 탐색, 방문자 수 계산 과 같은
실시간 분석 / 계산이 가능하다. - Redis 의 Pub / Sub 패턴을 활용하여 실시간 채팅을 쉽게 구현 가능하다.
Redis 의 Persistence
기본적으로 Redis 는 캐시로 사용되기 휘발되어도 괜찮은 데이터를 저장해야 한다. 하지만, 이런 캐시 데이터가 유실되었을때 서비스의 문제로 이어갈 수 있다. 이에 따라 Redis 는 안정적인 Cache 서버 운영을 위해 이러한 Cache 데이터를 영구저장(Persistence) 할 수 있는 기능을 제공한다.
RDB
RDB 는 Redis Database 를 의미하며 이를 통해 장애가 발생하였을 때 장애가 발생하기 특정 시점의 Snapshot 으로 Cache 를 장애가 발생하기 전으로 되돌리거나 동일한 데이터를 가진 Cache 를 복제할때 주로 사용된다. 하지만 Snapshot 이 생성되기 이전의 데이터가 유실될 수 있고, Snapshot 생성 중에 Client 에 요청 Latency(지연) 이 발생할 수 있다.
AOF
AOF 는 Append Only File 이라는 옵션으로 Redis 에 적용되는 모든 Write 작업을 로그로 저장하는 기술을 의미한다. 데이터의 유실없이 모든 데이터의 Sync 를 맞출 수 있지만, 재난 복구 시 Write 작업을 다시 적용하기 때문에 Snapshot 을 이용한 RDB 방식보다 느릴 수 있다.
Redis 의 Cache
Cache (캐시) 는 데이터를 빠르게 읽고 처리하기 위해 속도가 빠른 메모리를 활용하여 임시로 저장하는 기술을 의미한다. 계산된 값을 캐시에 저장해 동일한 요청이 들어오거나 동일한 값이 필요할 때 다시 계산하지 않고, 빠르게 결과값을 전달하기 위해 사용한다.
대표적으로 CPU 와 RAM 의 속도 차이로 발생하는 지연을 줄이기 위한 L1, L2, L3 캐시, Web Browser 캐시, AWS CloudFront 의 Edge Network 과 비슷한 개념인 CDN, 도메인 주소와 IP 주소를 연결하는 DNS 에 대한 캐시인 DNS 캐시, 그리고 JPA 의 영속성 컨텍스트의 1차 캐시가 있다.
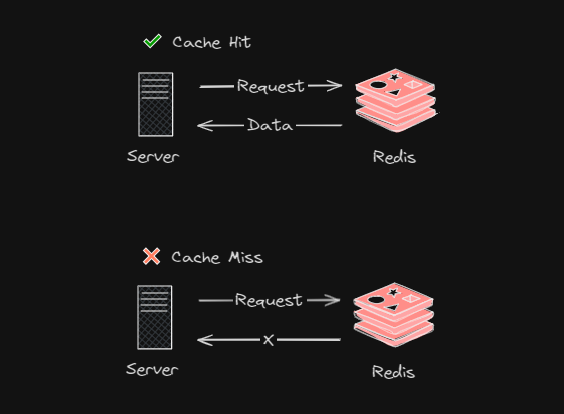
Cache Hit & Cache Miss
Redis 서버에 저장된 특정 Key 값을 갖는 Cache 데이터를 요청했을 때 정상적으로 응답이 온것을 Cache Hit 라고 표현하며 Key 값이 없거나 Key 값이 만료되어 정상적으로 응답이 오지 않는 것을 Cache Miss 라고 표현한다.
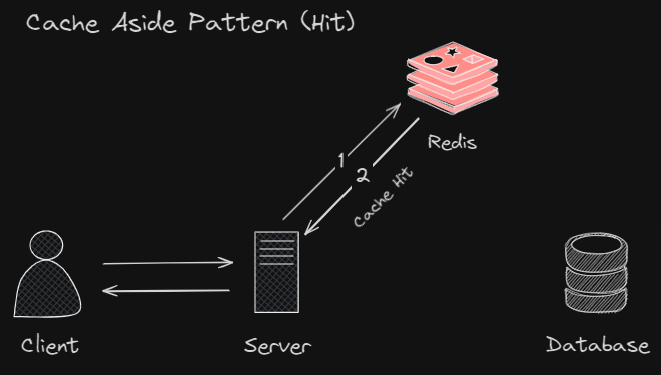
Cache Aside Pattern
Cache Aside Pattern 은 애플리케이션에서 Client 의 요청을 처리할때 먼저 Redis 서버에서 Cache 를 조회한 다음 Cache Hit 면 Cache 값을 응답해주고 Cache Miss 면 DB 에서 데이터를 조회하여 반환 후, Redis 서버에 Write Cache 를 하여 데이터를 캐싱시키는 것을 의미한다.
Cache Hit 일 경우 아래와 같이 동작.
Cache Miss 일 경우 아래와 같이 동작.
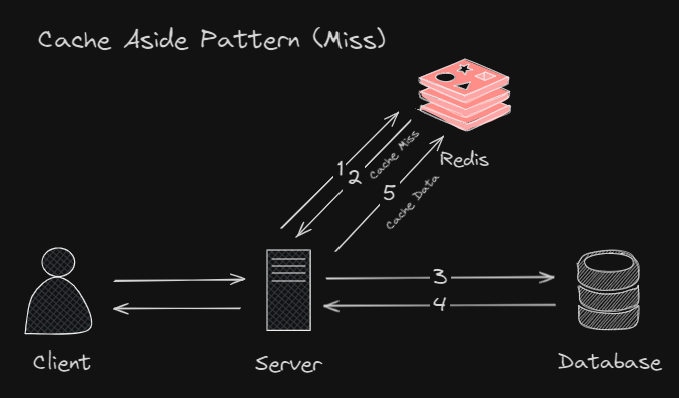
Cache 를 사용하는 패턴 중, 가장 많이 쓰이는 패턴이며 Write Through, Write Behind 같은 패턴도 있지만 자주 사용된 않는다.
Redis 설치 및 실행
Parrot OS(Debian) 기준 아래의 명령어를 통해 Docker 를 받은 후, Docker 환경에서 Redis 를 설치하여 Redis 프롬프트에 접근할 수 있음.
$ sudo apt update
$ sudo apt-get install docker.io -y
$ docker pull redis
$ docker run --name redis redis &
$ docker exec -it redis redis-cliRedis 동작 확인
ping 을 입력했을 때 PONG 이 오면 정상적으로 동작하는 것.

set 으로 특정 key 에 대한 value 를 설정할 수 있으며, get 으로 특정 key 에 대한 value 값을 가져올 수있다. 참고로 명령어들을 Ignore Case 이다.

특정 key 를 삭제하는 것은 del 로 가능하다. 1 을 리턴하면 잘 동작했다는 의미이다. 또이제 삭제한 key 를 get 해보면 nil 이 나오는데 redis 에서 nil 은 데이터가 없다는 것을 의미한다.

Redis 의 DataType
Strings
문자열, 숫자, 직렬화된 객체(JSON String) 을 저장할 수 있다.
| Syntax | Description |
|---|---|
set KEY VALUE | 단일 Key 에 대한 String Value 값을 설정 |
mset KEY VALUE KEY VALUE … | multi set 의 약자로 다수개의 Key 에 대한 String Value 를 설정할 수 있다. |
get KEY | 단일 Key 에 대한 String Value 값을 가져온다 |
mget KEY KEY KEY … | multi get 의 약자로 다수개의 Key 에 대한 String Value 값을 가져올 수 있다. |
incr price | price 라는 key 의 값을 1 증가시킨다 |
incrby price NUM | price 라는 key 의 값을 NUM 만큼 증가시킨다 |
set jsonstring ’{“key”: 100, “value”: “test”}‘ | jsonstring 이라는 key 값에 json string 을 저장. 사용할때는 json 으로 다시 변환해야 한다. |
set name:name:name revi1337 | name:name:name 이라는 키 값은 revi1337 이다. 자주 사용되는 네이밍 컨벤션 |
Lists
String 을 LinkedList 로 저장하는 데이터타입이다. 이중연결 리스트 라고 보면 되며 push/pop 에 최적화 되어있어, Queue 나 Stack 을 구현할 수 있다.
| Syntax | Description |
|---|---|
lpush NAME VALUE VALUE VALUE … | NAME 이라는 이중연결 리스트에 왼쪽부터 VALUE 들을 삽입한다. |
rpop NAME | Queue (FIFO) NAME 이라는 이중연결 리스트의 맨오른쪽 값을 꺼낸다. |
lpop NAME | Stack (LIFO) NAME 이라는 이중연결 리스트의 맨왼쪽 값을 꺼낸다. |
lrange NAME -2 -1 | Index 를 이용해 다수개의 값을 출력. 오른쪽에서 세면 0 부터 증가하며 왼쪽에서 세면 -1 부터 점차 감소한다. |
ltrim NAME 0 0 | 가장 마지막에 추가된 item 만 남기고 나머지는 모두 삭제한다. |
List 의 모든 값 출력은
lrange NAME 0 -1이 된다.
Sets
Uniq String 을 저장하는 정렬되지 않은 집합. Set Operation 사용가능 (intersection, union, difference)
| Syntax | Description |
|---|---|
sadd NAME VALUE VALUE VALUE | NAME 이라는 Set 에 VALUE 데이터들을 추가 (중복 X) |
smembers NAME | NAME 이라는 Set 멤버들을 모두 출력 |
scard NAME | NAME 라는 Set 멤버들중에서 Uniq 한 멤버들의 개수 출력 |
sinter NAME1 NAME2 | NAME1 라는 Set 와 NAME2 Set 의 교집합 멤버 출력 |
sdiff NAME1 NAME2 | NAME1 라는 Set 와 NAME2 Set 의 차집합 멤버 출력 |
sunion NAME1 NAME2 | NAME1 라는 Set 와 NAME2 Set 에 합집합 멤버 출력 |
sismember NAME VALUE | NAME 라는 Set 에 VALUE 라는 멤버가 있는 확인 |
Hashs
Field-Value 구조를 갖는 데이터 타입이며, 다양한 속성을 갖는 객체의 데이터를 저장할 때 유용하다. Dictionary 와 Map 을 생각하면 편하다.
| Syntax | Description |
|---|---|
hset NAME KEY VALUE KEY VALUE … | 다수의 KEY:VALUE 형태의 데이터를 NAME 이라는 hash 에 삽입 |
hmget NAME KEY KEY KEY | NAME 이라는 hash 에서 다수개의 KEY 애 대한 VALUE 들을 출력 |
hincrby NAME KEY NUM | NAME 이라는 hash 에서 KEY 의 VALUE 를 꺼내 NUM 만큼 수를 increase 한다 |
hget NAME KEY | NAME 이라는 hash 에서 단일개의 KEY 에 대한 VALUE 를 출력 |
hgetall NAME | NAME 이라는 hash 에서 KEY VALUE 들을 모두 출력. |
Sorted Sets
Uniq String 을 저장하는 정렬되지 않은 집합인 Set 와 유사하지만 score 라는 추가적인 필드를 갖음으로서 해당 score 를 통해 데이터를 미리 정렬하는 데이터타입이다. ZSets 이라고 불리우며 Redis 만의 독특한 데이터 타입 중 하나이다. 또한 내부적으로 Skip List + Hash Table 로 이루어져 있으며 내부 구현에 따라 값을 추가하는 순간 score 에 의해 값의 정렬을 유지하게 된다. 만약 score 가 동일하면 사전 편찬 순 으로 정렬하게 된다.
| Syntax | Description |
|---|---|
zadd NAME SCORE VALUE SCORE VALUE … | NAME 이라는 ZSets 에 VALUE 들을 저장한다. 이때 SCORE 순으로 저장되게 된다. |
zrange NAME IDX IDX | NAME 이라는 ZSets 에서 시작 IDX 부터 끝 IDX 의 VALUE 를 출력한다. 왼쪽부터 0에서 증가하고, 오른쪽부터 -1 에서 작아진다. |
zrange NAME IDX IDX REV | zrange NAME IDX IDX 의 역순. |
zrange NAME IDX IDX REV WITHSCORES | zrange NAME IDX IDX REV 에 SCORE 도 같이 반환. |
zrank NAME VALUE | NAME 이라는 ZSets 에서 VALUE 의 랭크를 반환한다. 이는 인덱스 값과 같기 때문에 해당 VLAUE 의 인덱스를 반환한다 보면 된다. |
Streams
append-only log 에 consumer groups 과 같은 기능을 더한 자료구조이다. 여기서 append-only log 는 db 나 분산시스템에 주로 사용되는 데이터 저장 알고리즘으로 데이터의 수정과 삭제는 되지않고 추가만 되는 구조를 갖는다.
xadd 스트림 를 통해 Stream 에 값을 생성하고 * 를 통해 Uniq 아이디를 자동으로 할당할 수 있다. * 이후에는 Hash 와 같은 Field Value 형태로 메시지를 구성할 수 있다.
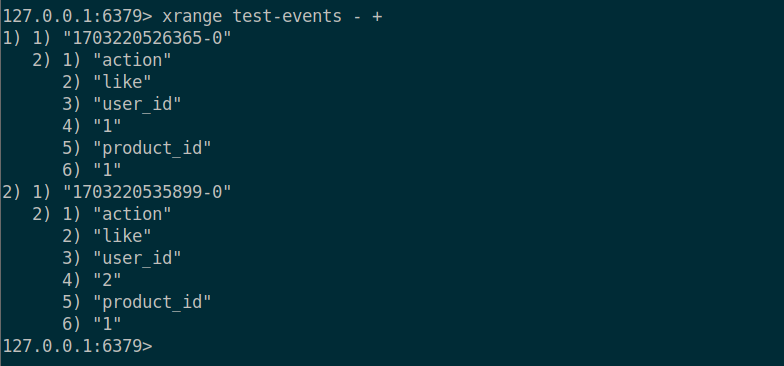
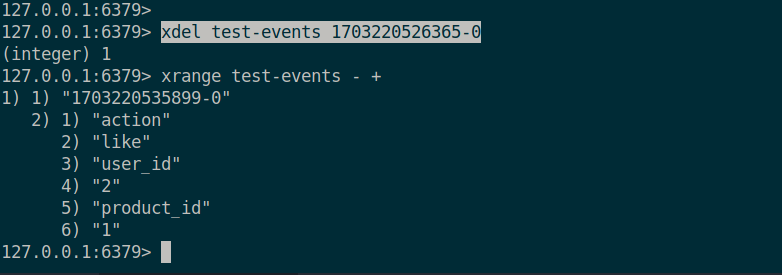
해당 명령어는 xadd 를 통해 test-events 라는 Stream 을 에 * 를 통해 Uniq 아이디를 자동으로 할당하며, test-events 라는 Stream 에 action 은 like, user_id 가 1, product_id 가 1 이라는 데이터를 저장할 수 있다. 데이터가 저장되고 출력된 숫자들은 식별자를 의미한다. - 를 기준으로 앞이 추가된 시간, 뒤에는 0 번째 item 이라는 것을 의미하기 때문에 해당 시간에 추가된 0번째 item 이라는 의미를 갖게 된다.

xrange 스트림 - + 를 통해 특정 Stream 에서 가장 처음으로 들어간 이벤트부터 제일 마지막에 추가된 이벤트순으로 볼 수 있다.
xdel 스트림 식별자 을 통해 사용한 이벤트 및 아이템을 삭제할 수 있다.
Geospatial
좌표를 저장하고, 검색할 수 있는 데이터타입이다. 거리 계산, 범위 탐색 등의 기능을 지원한다. LONGITUDE 는 경도를 의미하며 LATITUDE 는 위도를 의미한다.
| Syntax | Description |
|---|---|
geoadd NAME LONGITUDE LATITUDE MEMBER [LONGITUDE LATITUDE MEMBER …] | NAME 에 LONGITUDE LATITUDE 의 좌표를 갖는 MEMBER 들을 저장 |
geodist NAME MEMBER1 MEMBER2 [M|KM|FT|MI] | NAME 의 MEMBER1 와 MEMBERR2 의 거리를 출력 |
georadius NAME LONGITUDE LATITUDE DISTANCE M|KM|FT|MI | LONGITUDE LATITUDE 를 기준으로 DISTANCE (단위) 반경 이내에 있는 NAME 의 특정 MEMBER 들을 출력 (단위를 명시해야 함) |
geoadd 를 통해 seoul:station 에 우장산역과 발산역을 경도 위도를 저장.

geodist 를 통해 우장산역과 발산역의 거리를 출력한다. 이 때 단위는 선택사항이다.

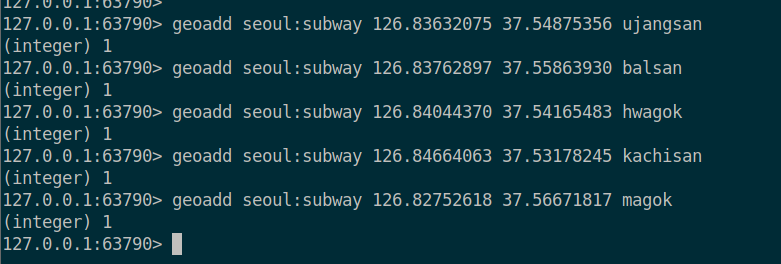
또한 아래와 같이 seoul:subway 라는 key 값으로 우장산, 발산, 화곡, 까치산, 마곡 이라는 MEMBER 들의 경도/위도 데이터를 저장해주고
georadius 로 경도/위도 를 기준으로 DISTANCE (단위) 이내에 있는 NAME 의 MEMBER 들도 알아낼 수 있다. 아래의 예시는 특정 경도/위도를 기준으로 2 KM 반경에 있는 seoul:subway 의 MEMBER 들을 출력한 것이다.

Bitmaps
실제 데이터 타입은 아니고, String 에 Binary Operation 을 적용한 것. 최대 42억개의 Binary 데이터를 표현할 수 있다. 매우 적은 메모리를 사용하기 때문에 굉장히 효율적으로 데이터를 관리할 수 있다.
Bitmaps 를 통해 특정 날짜에 접속한 사용자수를 계산할 수 있다. 아래사진은 특정날짜에 대한 사용자의 로그인 여부를 저장한것이다. 123, 456 은 사용자아이디를 의미하며, 1 은 접속했다는 것을 의미한다.

bitcount 를 통해 특정 날짜에 로그인한 사용자의 수 출력할 수 있다.

bitop 를 통해 명시한 날짜들에 모두 로그인한 사용자들의 수를 구할 수 있다. 두개의 날짜에 모두 접속한 사용자를 구해야 하니 AND 연산자를 사용하여 그 결과를 result 라는 새로운 bitmap 을 만들어서 저장한다. (기본적으로 bitop 의 결과값은 새로운 bitmap 을 만들어서 저장한다. 또한, operation 에는 OR, AND, XOR 이 가능하다.)

앞서 bitop 를 통해 특정 날짜들에 로그인한 사용자들의 수를 result 비트맵에 저장했다. 이는 bitcount 를 통해 확인할 수 있으며 총 1명이 나온것을 확인할 수 있다. 또한, getbit 를 통해 result 비트맵에 저장된 사용자들이 로그인했었는지 확인할 수 있다.

HyperLogLog
집합의 Cardinality 를 추정할 수 있는 확률형 자료구조이다. 정확성을 일부 포기하는 대신 저장공간을 효율적으로 사용한다 (평균 에러 0.81%) . HyperLogLog 는 실제 값을 저장하지 않기 때문에 모든 item 을 다시 출력해야하는 경우에는 활용할 수 없다
터미널에서 set 에 1000 개의 데이터를 넣어주는 커맨드를 백그라운드에서 돌려주고
$ for((i=0; i<=1000; i++)); do docker exec -it redis redis-cli sadd set-card $i; done &이어서 바로 pfadd 를 통해 HyperLogLog 에 1000 개의 데이터를 넣어주는 커맨드를 백그라운드에서 돌려주고 이 작업들이 끝날때까지 기다린다. 난 도커환경이라 이거 상당히 오래걸린다. ㅋㅋ;;
$ for((i=0; i<=1000; i++)); do docker exec -it redis redis-cli pfadd hyber-card $i; done &이제 pfcount 로 HyperLogLog 의 카디널리티를 확인해보면 1002 가 나온것을 볼 수 있다. 0.81 퍼세트 에러가 두번 터진것을 확인할 수 있다.

메모리 사용량을 보면 Set 보다 HyperLogLog 가 메모리 사용률이 몇십배 차이나는것을 볼 수 있다.

BloomFilter
element 가 집합 안에 포함되었는지 확인할 수 있는 확률형 자료구조이다. 멤버쉽 테스트라고 불리는 기능을 구현할 때 자주 사용된다. BloomFilter 도 HyperLogLog 처럼 정확성을 일부 포기하는 대신 저장공간을 효율적으로 사용하며 실제 값을 저장하지 않는다. 값이 집합에 포함되지 않는다는 사실은 정확하게 확인할 수 있지만 집합에 포함되지 않는 값이 존재한다고 잘못하는 false positive 가 일어난다. bf.madd 를 통해 집합에 item 을 추가할 수 있으며 bf.exists 를 통해 해당 item 이 집합에 포함되어있는지 확인할 수 있다.
BloomFilter 를 사용하기 위해서는 특정한 모듈이 필요하지만 도커로 대체할 수 있다.
$ docker run -p 63790:6379 -d --rm redis/redis-stack-server이제 BloomFilter 를 사용할 수있는 redis 서버에 연결해준다.

이제 bf.add 와 bf.madd 를 통해 집합에 값을 추가해줄 수 있다.

또한, bf.exists 로 특정 item 이 집합에 포함되어있는지 확인할 수 있다.
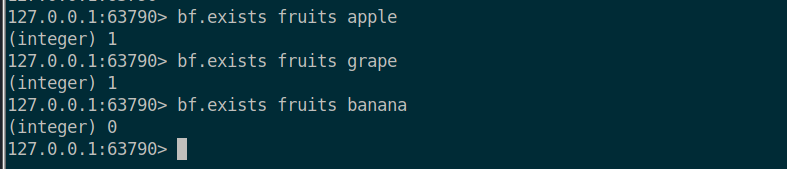
지금은 집합내부의 item 개수가 적어서 없는 값이 존재한다고 표현되는 false positivie 가 발생하지 않지만 집합 내부 item 의 개수가 많아지면 false positive 가 발생할 수 있다는 것을 염두하고, 대처방법을 생각해보아야 한다.
Redis 의 특수 명령어
Expiration
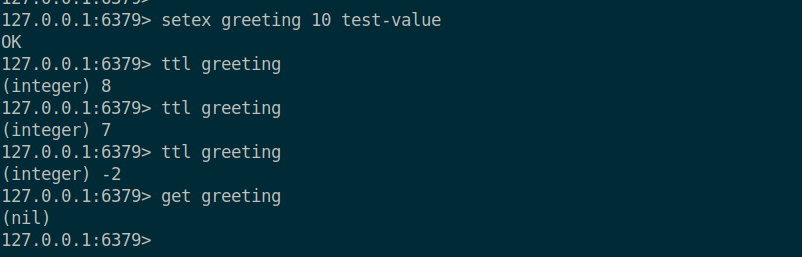
데이터를 특정 시간 이후에 만료시키는 기능. 보통 TTL(Time To Live) 를 통해 데이터가 유효한 시간(초) 를 설정하게 된다. set 으로 데이터를 설정하고 expire 명령어를 통해 데이터의 유효시간을 설정할 수 있다. 또한, ttl 명령어를 사용해서 남은 TTL 정보를 확인할 수 있으며 setex 를 이용해 데이터를 저장함과 동시에 만료시간을 동시에 지정할 수 있다.
set 으로 greeting 에 hello 를 저장하고 ttl 을 통해 만료시간을 확인해본다 여기서 -1 은 만료시간이 설정되어있지 않다는 의미이다.

이제 expire 로 greeting 에 10 초의 만료기간을 설정해준다. 이제 주기적으로 ttl 로 greeting 을 확인해보면 숫자가 줄어들다가 -2 가 출력됨을 확인할 수 있다.
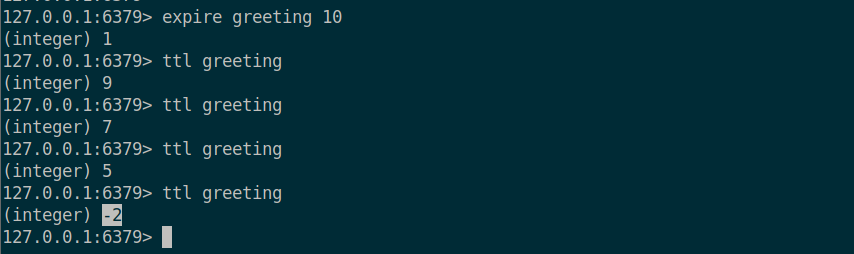
-2 는 해당 값이 만료되었다는 것을 의미하기때문에 get 으로 greeting 을 찾게되면 값이 없다는 의미인 nil 이 출력되는것을 알 수 있다.

추가적으로 setex 으로 데이터의 저장, 만료시간설정을 한번에 해줄 수 있다.
SET NX/XX
NX 는 해당 Key 의 데이터가 존재하지 않는 경우에만 새로운 데이터가 저장되는 옵션이다. 이와 반대로 XX 는 해당 Key 가 이미 존재하는 경우에만 데이터를 덮어쓰는 옵션이다. NX 옵션과 XX 옵션은 set 의 맨 뒤에 명시해주면 되며, set 이 동작하지 않으면 nil 을 응답하게 된다.
NX 테스트
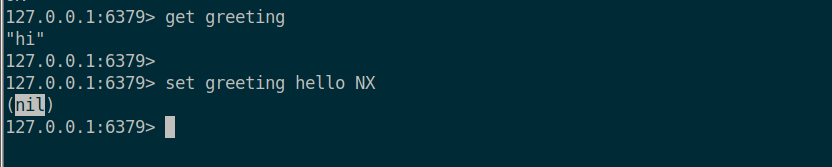
greeting 에 값을 설정해주고 값을 확인해준다.

이제 NX 를 사용해서 greeting 값을 Overwite 해보면 이미 greeting 에 값이 존재하기 때문에 set 가 동작하지 않아 nil 을 응답하는 것을 확인할 수 있다.
XX 테스트
이번에는 XX 옵션을 통해 greeting2 값을 설정해보면 nil 이 발생하는 것을 확인할 수 있다. 이는 greeting2 라는 값이 원래부터 없었기때문이다.

Pub/Sub
Publisher / Subscriber 라는 뜻으로 시스템 사이의 메시지를 통신하는 패턴중 하나이며 pub 과 sub 이 서로 알지 못해도 통신이 가능하도록 decoupling 되어 있는 패턴이다. publisher 는 subscriber 에게 직접 메시지를 보내지 않고, Channel 에 메시지를 publish 하게 된다. subscriber 는 관심이 있는 Channel 만 Subscribe 하여 메시지를 수신한다. 따라서 subscriber 의 기능이 변경되어도 publisher 는 이를 신경쓰지 않아도 된다는 것이다. Redis Stream 과 다른점은 발생된 메시지가 보관되는 Stream 과 달리 Pub/Sub 은 이미 발생된 메시지를 다시 수신할 수 없다.
subscribe 명령어로 특정한 Channel 을 구독할 수 있으며, publish 명령어로 원하는 Channel 에 메시지를 보낼 수 있다.
| Syntax | Description |
|---|---|
subscribe CHANNEL [CHANNEL …] | CHANNL 을 구독 |
publish CHANNEL MESSAGE | CHANNEL 에 MESSAGE 를 퍼블리시 (전송) |
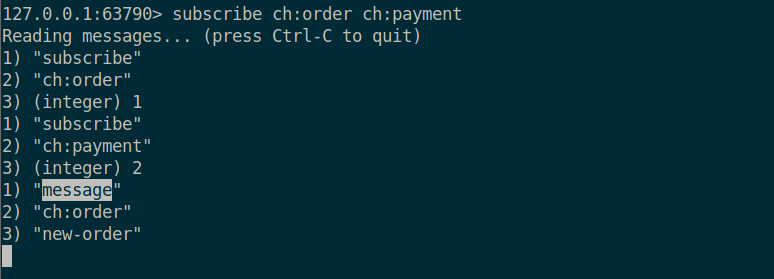
아래와 같이 subscribe 로 특정한 ch:order 와 ch:payment 라는 채널을 구독해주고
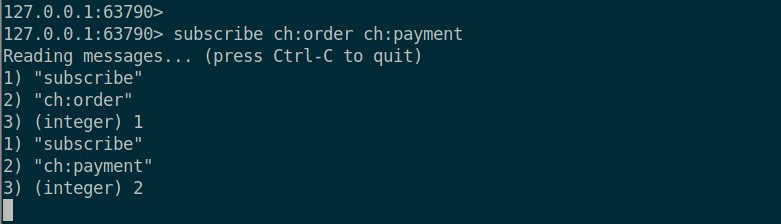
또 다른 터미널에서 publish 로 메시지를 퍼블리시해주면

원래의 터미널에서 message 라는 타입이 publish 되었다는 것을 확인할 수 있고, ch:order 라는 채널로부터 new-order 라는 메시지가 전달된것을 확인할 수 있다.
하지만, publisher 쪽에서 존재하지 않는 Channel 에 대해 메시지를 publish 하려하면 아무것도 영향을 받지않는 것을 확인할 수 있다. (integer) 0

Transaction
다수의 명령을 하나의 트랜잭션 단위로 묶어 처리하는 것. 기본적으로 원자성이 보장된다. 따라서 하나의 트랜잭션에 속한 다수의 명령을 처리하다가 오류 혹은 예외가 발생하면 모든 작업을 Rollback 하게 된다. 하나의 트랜잭션이 처리되는 동안 Client 의 요청이 중간에 끼어들 수 없다.
원자성(Atomic) 이란 모든 작업이 적용되거나 하나도 적용되지 않는 특성을 의미한다.
multi 명령어로 트랜잭션을 시작할 수 있고, 이 후 트랜잭션에서 처리할 명령들을 입력해주면 된다. 마지막으로는 discard 로 롤백시킬 수 있고, exec 로 커밋시킬 수 있다.
아래 사진에서처럼 multi 로 트랜잭션을 시작해주면 프롬프트에 TX 가 추가되며 트랜잭션이 시작 된다.

여기서 특정한 명령어를 추가해주면 QUEUED 라는 것이 출력된다. 이는 실제로 foo 라는 key 에 1을 증가시키라는 작업이 큐에 들어갔다는 의미이다.

작업이 큐에 들어갔을 뿐 아직은 아직은 실제로 처리되지 않았기 때문에 discard 를 통해 롤백시켜 주고 foo 를 확인해주면 어떠한 값이 저장되지 않은것을 볼 수 있다.

하지만, discard 를 수행하지 않고, exec 를 통해 커밋을 해주면 큐에 들어가있던 작업들이 수행되어 foo 에 값이 저장된것을 확인할 수 있다.

Redis 주의할 점
O(N) 명령어
Redis 의 대부분의 명령어들은 O(1) 의 시간복잡도를 갖기 때문에 굉장히 빠르게 동작하지만 일부 명령어들은 O(N) 의 시간복잡도를 갖는다. 또한 Redis 는 Single Thread 로 명령어를 순차적으로 수행하기 때문에 오래 걸리는 O(N) 명령어 시, 전체적인 어플리케이션 성능 저하르 이어질 수 있다.
대표적으로 O(N) 시간복잡도를 갖는 명령들은 keys 이다. keys * 를 쓰게 되면 모든 Redis 에 저장된 모든 key 들을 조회하기 때문에 프로덕션에서 절대 사용하면 안된다. 특정 패턴에 맞는 key 를 조회하기위해서는 반드시 scan 명령어로 대체하도록 하자. 이는 del 도 마찬가지이며 del 은 unlink 로 대체할 수 있다.
또한, set 의 모든 MEMBER 들을 출력하는 smembers 도 O(N) 의 시간복잡도를 갖는다. set 내부 MEMBER 의 수가 많을수록 오래걸리게 된다. 하나의 set 에 만개이상 데이터를 넣는것보다 set 을 분리하는것이 낫다.
마지막으로 hash 의 모든 field 를 반환하는 hgetall 도 O(N) 으로 동작하기 때문에 조심해야한다.
대체할 수 있는 커맨드를 정리하면 아래와 같다.
keys *를scan으로 대체hgetall을hscan으로 대체del을unlink로 대체
Thundering Herd Problem
병렬 요청이 공유 자원에 대해서 접근할 때, 급격한 과부하가 발생하는 문제이다. Cache 만료에 의해 발생할 수 있다. 따라서 이를 해결하기 위해서는 별도의 Process 에서 Cronjob 을 통해 Cache 를 최신화시켜주는 방법이 있을 수 있다.
Stale Cache Invalidation
Cache 의 유효성이 손실되었거나 변경되었을 때, 캐시를 변경하거나 삭제하는 기술을 의미한다. 유효하지 않은 Cache 를 계속 갖고있을면 어플리케이션에서 잘못된 데이터를 내려줄 수 있게 때문에 이것을 고려해야 한다.
참고
해당 글은 인프런 신동현 강사님의 실전! Redis 활용 강의를 보며 작성했습니다.