Index 란
- RDBMS 에서 검색 속도를 높이기 위한 기술이며, 책의 맨앞 혹은 맨뒤에 있는 색인(목차) 로 비유할 수 있다.
- Table 에 저장되어 있는 Record (row) 중에서
특정 조건을 만족하는 Record 들을 빠르게 찾기 위해 사용한다.
Index 의 자료구조
B-Tree
- 대부분의 RDBMS 에서는 B-Tree (Tree) 와 같은 자료구조를 사용해서 인덱스를 관리한다.
- B-Tree 는 BST(Binary Search Tree) 를 일반화시킨 트리이다.
- B-Tree 는 Balanced Tree 형태를 유지하고
정렬되어 있기때문에O(logN)이라는 빠른 속도로 탐색할 수 있다. 이는 테이블 전체를 스캔하는Full Scan이O(N)의 시간복잡도를 갖는것과 비교하면 굉장히 빠른 탐색 속도이다. - 인덱스를 사용하면
탐색 효율이 증가한다는 장점도 있지만, 데이터의 변경CUD(Insert, Update, Delete). 즉, DML 쿼리를 수행할때 드는 비용이 증가한다.
HashTable
- Column 값을 해싱하여 인덱스를 관리하는 방법이다. 해싱한 값을 Key : Value 와 같은 형태로 관리하므로 매우 빠른 탐색 속도를 갖는다.
O(1) - 하지만 Column 값을 해싱. 즉 Column 값을 변경하기 때문에 Equals(=) 를 제외한 Range Scan (>, <, Like, Between) 이 불가하다.
- Redis 와 같은 메모리 기반의 데이터베이스에서 많이 사용된다.
B-Tree vs HashTable
- Index 를 HashTable 로 관리하면 특정 Column 에 대해 O(1) 시간복잡도로 빠른 탐색이 가능하지만, 기존 Column 값을 변경(해시) 하기 때문에 RangeScan 이 불가능하다.
- 즉, 단 하나의 데이터를 탐색할때만 효율적일 뿐 B-Tree 에 비해 득보다 실이 더 많다.
B-Tree vs RedBlack-Tree(BST)
RedBlack-Tree 는 BST 중에서도 가장 빠르다고 알려져있으며 리눅스의 FileSystem, 다양한 언어의 STL 등 많은 곳에서 사용되는 자료구조이다. 그럼에도 인덱스 관리를 일반적으로 RedBlack-Tree 가 아닌 B-Tree 로 하는 이유는 저장매체의 특성 차이 때문이다.
현재까지 상당수의 RDB 는 데이터를 HDD(하드디스크) 에 저장하게 되는데 HDD 는 순차읽기(Sequence Access) 성능은 준수하지만 Random Access 와 쓰기성능에서는 상대적으로 느린 특성을 갖고있다. (헤더가 데이터의 저장 위치를 찾는 시간이 소요되기 때문)
Tree 는 추상화된 구조인데 내부적으로 LinkedList 같은 자료구조를 통해서 실질적으로 구현이 된다. 즉, prevNode, nextNode 등 노드끼리의 이동은 주소값을 통해서 탐색하게 된다. 따라서 CUD 하려는 데이터에 접근하기까지 지속적인 Random Access 가 일어나게 되어 HDD 에서 성능이 저하될 수 있다.
그렇기 때문에 하나의 Node 에 하나의 값만 들어갈 수 있는 RedBlack-Tree 보다 하나의 Node 에 여러개의 값(배열과 같은 형태)이 들어갈 수 있는 B-Tree 가 성능상 더 유리하다. (Random Access 가 더 적고 순차읽기가 더 많기 때문)
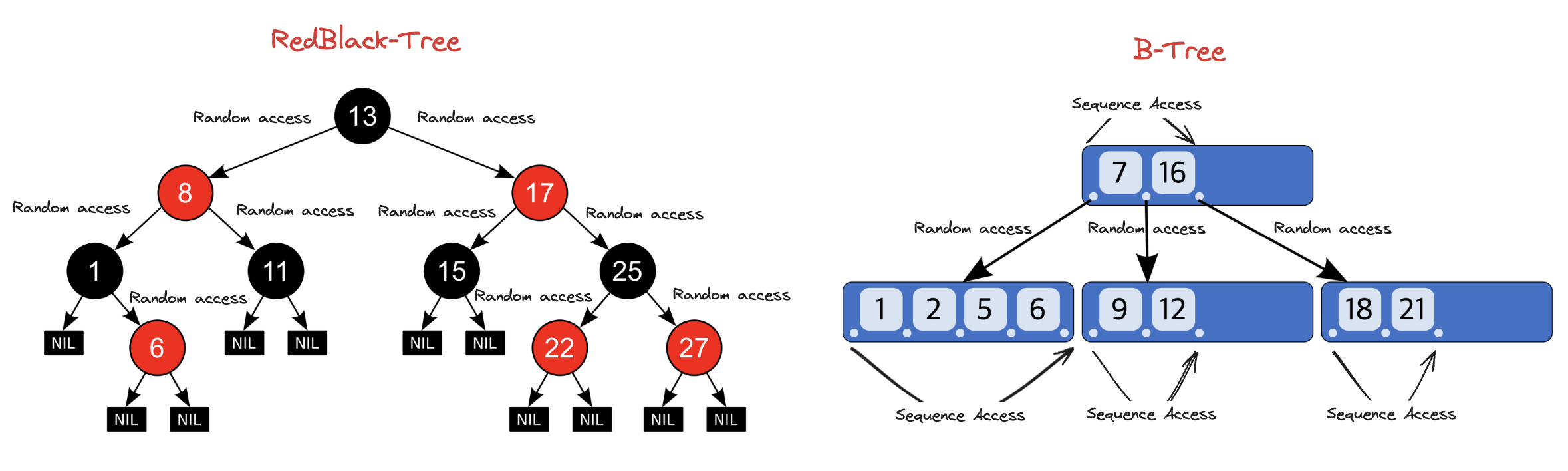
결론적으로 데이터가 In-Memory 가 아닌 HDD 에 저장된 상황에서는 상대적으로 Random Access 가 더 적고, CUD 에 오버헤드가 더 적은 B-Tree 가 RedBlack-Tree(BST) 보다 성능이 더 좋다.
Index 의 장점
- 인덱스를 사용하면
탐색 효율이 증가하게 된다.
Index 의 단점
- 인덱스를 사용하면
탐색 효율이 증가하는 장점과는 반대로, 데이터의 변경CUD(Insert, Update, Delete). 즉, DML 쿼리를 사용할때 드는 비용이 증가한다.