자연키 및 인조키
자연키 는 실제 데이터의 속성 값을 키로 사용하는 것을 말하며, 인조키는 실제 데이터와 무관하게 키로 사용하기 위한 새로운 값을 만들어 사용하는 것을 말합니다.
회원번호 및 주민번호가 자연키가 될 수 있고, UUID 가 인조키가 될 수 있습니다.
JPA 영속성 객체
자연키 및 인조키를 사용한 영속성 객체는 아래와 같이 나타낼 수 있습니다. 유의깊게 봐야할 부분은 PK 값을 자동으로 올려주게(auto_increment) 하는 @GeneratedValue 를 사용하지 않았다는 것입니다.
@Getter
@AllArgsConstructor(access = AccessLevel.PRIVATE)
@NoArgsConstructor(access = AccessLevel.PROTECTED)
@Entity
public class Category {
@Id // @GeneratedValue 를 사용하지 않았음.
private Long id;
@Column(name = "name", nullable = false)
private String name;
public static Category create(Long id, String name) {
return new Category(id, name);
}
}자연키 사용시 주의점
자연키 및 인조키 사용하고, DataJPA 를 사용한다면 save() 를 호출할때 조심해야 합니다. 그렇지 않으면 단순하게 save() 만 호출했을 뿐인데 불필요한 SELECT 문이 날라간 뒤, INSERT 가 날라가서 총 2개의 쿼리가 나가게 됩니다.
@DataJpaTest(showSql = false)
@AutoConfigureTestDatabase(replace = AutoConfigureTestDatabase.Replace.NONE)
class CategoryRepositoryTest {
@Autowired
private CategoryRepository categoryRepository;
@Test
@Rollback(false)
public void persistCategoryTest() {
Category category1 = Category.create(1L, "category1"); // 직접 PK(ID) 를 설정
categoryRepository.save(category1);
}
}Hibernate:
select
c1_0.id,
c1_0.name
from
category c1_0
where
c1_0.id=?
Hibernate:
insert
into
category
(name, id)
values
(?, ?)왜?
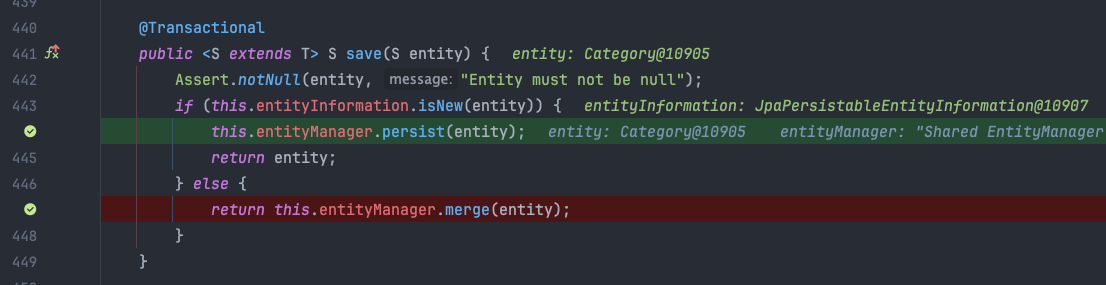
INSERT 전에 불필요한 SELECT 쿼리가 나가는 이유는 DataJPA 의 save() 동작방식 때문입니다. save 메서드가 호출되면 isNew() 메서드를 통해 매개변수로 들어온 객체가 비영속 상태인지 준영속 상태인지 판단하게 됩니다.
엔티티의 생명주기
비영속 : 영속성 객체와 관련이 없는 상태 영속 : 영속성 컨텍스트에 저장된 상태 준영속 : 영속성 컨텍스트에 저장되었다가 분리된 상태 삭제 : 삭제된 상태
만약 준영속 엔티티라고 판단되면, 이 준영속 엔티티를 다시 영속화 시키기 위해 merge() 가 호출되게 됩니다. 그게 아니고 비영속 엔티티라고 판단되면 이를 영속화 시키기 위해 persist() 를 호출하게 됩니다.
SimpleJpaRepository
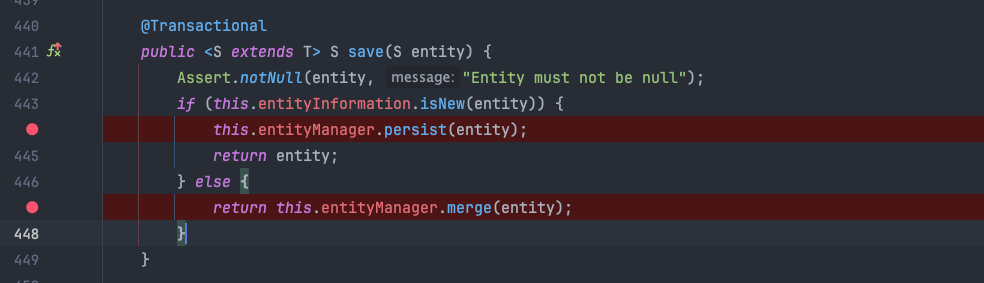
isNew 동작 원리
새로운 엔티티인지 (비영속 객체인지, 준영속 객체인지) 판단하는 isNew() 메서드에서는 @Id 태그가 달린 필드의 타입을 가져온 다음, 타입을 검사하게 됩니다. 조금 더 구체적으로는 ID 필드가 Number 인스턴스이고 0일 경우 와 Reference 타입이고 null 인 경우에만 새로운 엔티티(비영속) 엔티티라 판단하고, 나머지는 준영속엔티티라고 판단합니다.
JpaMetamodelEntityInformation(AbstractEntityInformation)
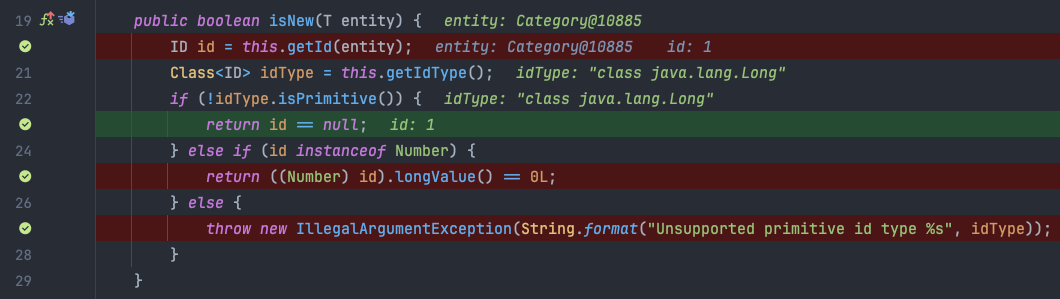
돌아와서
이는 결국 엔티티를 준영속 상태로 취급하게 되어, 객체를 다시 영속성 컨텍스트에 저장(영속화) 시키기 위해 merge() 가 호출되게 됩니다.
SimpleJpaRepository
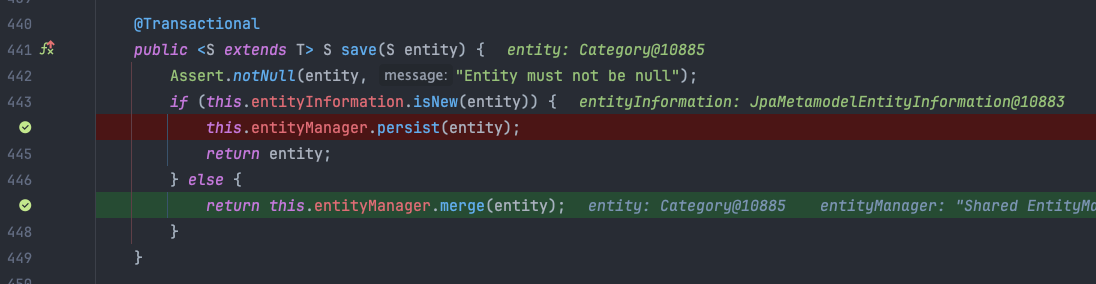
merge() 동작 원리
merge() 가 호출되면, JPA 는 준영속 상태의 객체를 영속 상태로 만들고자 시도합니다. 이를 위해 영속성 컨텍스트(1차 캐시) 에 해당 엔티티가 있는지 먼저 확인하고, 없다면 DB 에서 엔티티를 조회하여 영속성 컨텍스트(1차 캐시) 에 저장하게 됩니다.
우리는 자연키를 사용중이기 때문에, 당연히 영속성 컨텍스트(1차 캐시) 에 해당 객체가 없을것이고, 결국 DB 에 SELECT 쿼리를 날려 자연키에 맞는 데이터를 조회 후, 영속성 컨텍스트에 저장하는 과정을 거치게 됩니다.
따라서 자연키를 사용하게 되면, JPA 에서는 굉장히 높은 확률로 준영속 엔티티라고 판단하여 이를 다시 영속화시키기 위해 추가적인 SELECT 쿼리 가 나가게 됩니다.
후에 SELECT 쿼리로 갖고온 결과에 따라 INSERT 문이 나갈지 Update 문이 나갈지 결정됩니다.
DataJPA Persistable
불필요한 SELECT 쿼리가 나가는것을 해결하기 위해서는 새로운 엔티티를 판별하는 isNew() 메서드의 결과를 True 로 만들어야 한다.
SimpleJpaRepository
DataJPA 에서는 새로운 엔티티인지 여부를 판단하는 isNew() 메서드를 오버라이딩 할 수 있게 Persistable Interface 를 제공한다.
public interface Persistable<ID> {
@Nullable
ID getId();
boolean isNew();
}이제 Persistable 를 아래와 같이 구현해준다. getId() 의 오버라이딩은 Lombok 의 Getter 가 해결해주었다. 중요한 것은 @Transient 부분과 @PrePersist EntityListener 이다.
@Getter
@NoArgsConstructor(access = AccessLevel.PROTECTED)
@Entity
public class Category implements Persistable<Long> {
@Id
private Long id;
@Column(name = "name", nullable = false)
private String name;
@Transient
private boolean isNew = true;
private Category(Long id, String name) {
this.id = id;
this.name = name;
}
@Override
public boolean isNew() {
return isNew;
}
@PrePersist
@PostLoad
private void markNotNew() {
this.isNew = false;
}
public static Category create(Long id, String name) {
return new Category(id, name);
}
}자세한 설명은 아래와 같다.
- isNew 필드를 true 로 초기화시켜주고, @Transient 를 달아준다
- @Transient 는 영속화할 떄, 제외할 필드를 정해줄 수 있는 어노테이션이다. 영속화되지 않는 필드이기 때문에, 당연히 DB 에 Column 이 생기지 않는다.
- 오버라이딩한 isNew() 메서드의 결과를 앞서 선언한
isNew필드값으로 대체한다.- isNew 의 초기값이 true 이기 때문에, save 를 실행할때 내부에서 호출되는 isNew() 의 결과로 무조건 True 가 반환되어 비영속 엔티티로 취급되게 된다. 그 결과로 merge() 가 호출되지 않고, persist() 가 호출되게 된다.
- persist() 를 통해 객체를 영속화시키고 나면,
@PrePersistEntityListener 가 markNotNew() 를 호출하여 isNew 필드를 false 로 변경하게 된다. 때문에 두번째 save 부터는isNew()의 결과가 False 가 되어, 준영속 객체로 취급받게 된다.
왜 @PrePersist 인가
개인적으로 Persistable 문서를 보면서 궁금한 것이 있었다. persist() 가 끝나고 isNew 필드를 바꿔주어야하는데, 왜 @PostPersist 가 아니라 @PrePersist 일까? 라는 고민이었다. 결론부터 말하자면 두 어노테이션의 실행 시점이 다르기 떄문이다.
디버깅 결과 일단 @PrePersist 는 persist() 후에 호출되는 것을 알 수 있었다.
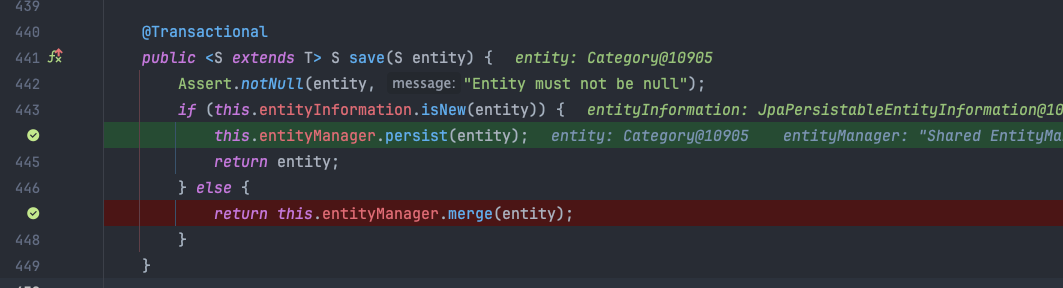
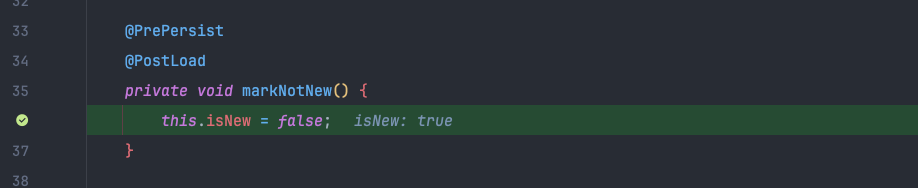
isNew()가 실행되는 시점은 persist 이전 persist/merge 를 구분하는 시점이다.@PrePersist가 실행되는 시점은 persist 가 호출되기 직전이다.- 따라서
@PrePersist를 통해 isNew 필드의 값을 바꿔줘도 아무런 문제가 없다.
해결
이제 테스트 코드를 조금 수정해서 실행해보면 save() 내부 isNew() 에서 True 를 반환하게 된다. 즉, 비영속 객체로 판단되었기 때문에 persist() 가 호출되는 것을 확인할 수 있다. 그리고 당연하게도 SELECT 쿼리가 나가지 않게 된다.
@DataJpaTest(showSql = false)
@AutoConfigureTestDatabase(replace = AutoConfigureTestDatabase.Replace.NONE)
class CategoryRepositoryTest {
@Autowired
private CategoryRepository categoryRepository;
@Test
@Rollback(false)
public void persistCategoryTest() {
Category category1 = Category.create(1L, "category1");
categoryRepository.save(category1); // 영속 --> 영속성 컨텍스트(1차 캐시)에 저장.
categoryRepository.save(category1); // 준영속 --> 영속성 컨텍스트(1차 캐시) 에 존재해서 DB 조회를 하지 않고, 1차 캐시에서 값을 가져옴.(동일성)
}
}
Hibernate:
insert
into
category
(name, id)
values
(?, ?)SimpleJpaRepository SessionImpl AbstractSaveEventListener DefaultPersistEventListener EntityInsertAction
AbstractSaveEventListener
- saveWithGeneratedId() 메서드에서 GeneratedValue 가 있는지 확인하고 performSave() 를 호출
- performSave()
- id 를 생성하기 전에 callbackRegistry.preCreate() 를 통해 id 필드를 가져온다.
- 이후, @PrePersist 가 호출된다.(정확히는 Reflection 을 통해)
- persister.getIdentifier() 를 통해 @Id 가 달려있는 Field 에 접근해 Key 를 가져온다.
- performSaveOrReplicate() 를 호출한다.
- id 를 생성하기 전에 callbackRegistry.preCreate() 를 통해 id 필드를 가져온다.
- performSaveOrReplicate()
- Key 가 있는지 없는지 확인하고, 있으면 Key 값을 가져온다.
- 여기서 Cascade 관련 동작 수행(cascadeBeforeSave() 그리고 cascadeAfterSave)
EntityInsertAction preInsert() persister.getInsertCoordinator().insert() 여기서 쿼리가 실행 postInsert()