프로젝트를 하다가 프론트엔드 한명이 카테고리를 DB 에 관리해달라는 요구사항이 들어왔다. 어짜피 카테고리별 조회 기능도 없고, 카테고리를 추가할 수 없는 기능도 없는데.. 굳이? 라는 생각이 잠깐 들었지만, 그래도 요구사항이니 그냥 하기로 했다. 이 포스팅에서는 요구사항을 처리하는 과정에서 1차 정규화의 대상이 되는 테이블을 정규화시킨 것과 N:M 관계를 풀어나간 과정을 간단히 적고자 한다.
1차 정규화
하나의 컬럼에 여러 도메인값을 포함하고있다면, 이는 1 차 정규화의 대상이 된다. 마찬가지로 프로젝트 내 Category 는 영속성 객체로 관리하지 않고, 카테고리1,카테고리2,카테고리3 처럼 하나의 컬럼에 도메값을 저장시켰기 때문에 1차 정규화의 대상이 된다. 그렇기 때문에 Category 를 별도의 테이블로 분리시켜주어야 한다.
CategoryType
카테고리가 동적으로 추가될 수 있다는 요구사항은 없었기 때문에, Enum 을 이용하여 허용 가능한 카테고리를 선언해주는것은 변함이 없다. 하지만 기존과 달라진 점은 pk 라는 필드를 선언해주었다는 것이다. 이는 해당 필드를 이용하여 CategoryType 을 사용하는 Entity 의 PK 를 정의하기 위해서이다.
@Getter
@RequiredArgsConstructor
public enum CategoryType {
... 생략
ESCAPEROOM("방탈출", 25L),
MANGACAFE("만화카페", 26L),
VR("VR", 27L),
... 생략
private final String text;
private final Long pk;
private static final Map<String, CategoryType> categoryHashMap = Collections.unmodifiableMap(new HashMap<>() {
{ unmodifiableLists().forEach(category -> put(category.getText(), category)); }
});
public static List<CategoryType> unmodifiableLists() {
return List.of(CategoryType.values());
}
public static List<CategoryType> fromTexts(List<String> categoryTexts) {
return new LinkedHashSet<>(categoryTexts).stream()
.map(CategoryType::mapFromText)
.peek(CategoryType::validateCategory)
.collect(Collectors.toList());
}
public static CategoryType mapFromText(String categoryText) {
return categoryHashMap.get(categoryText);
}
private static void validateCategory(CategoryType categoryType) {
if (categoryType == null) {
throw new IllegalArgumentException("일치하지 않는 카테고리가 존재합니다.");
}
}
}Category
CategoryType 을 이용하는 Category 엔티티를 새로 만들어준다. 그리고 Category 의 PK 는 CategoryType 의 pk 필드를 이용하여 직접 명시적으로 선언해준다.
@Getter
@NoArgsConstructor(access = AccessLevel.PROTECTED)
@Entity
public class Category {
@Id // @GeneratedValue 쓰지 않음.
private Long id;
@Enumerated(EnumType.STRING)
@Column(nullable = false)
private CategoryType categoryType;
private Category(CategoryType categoryType) {
this.id = categoryType.getPk();
this.categoryType = categoryType;
}
public static List<Category> fromCategoryTypes(List<CategoryType> categoryTypes) {
return categoryTypes.stream()
.map(Category::fromCategoryType)
.collect(Collectors.toList());
}
public static Category fromCategoryType(CategoryType categoryType) {
return new Category(categoryType);
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (!(o instanceof Category category)) return false;
return id != null && Objects.equals(getId(), category.getId());
}
@Override
public int hashCode() {
return Objects.hashCode(getId());
}
}테이블 확인
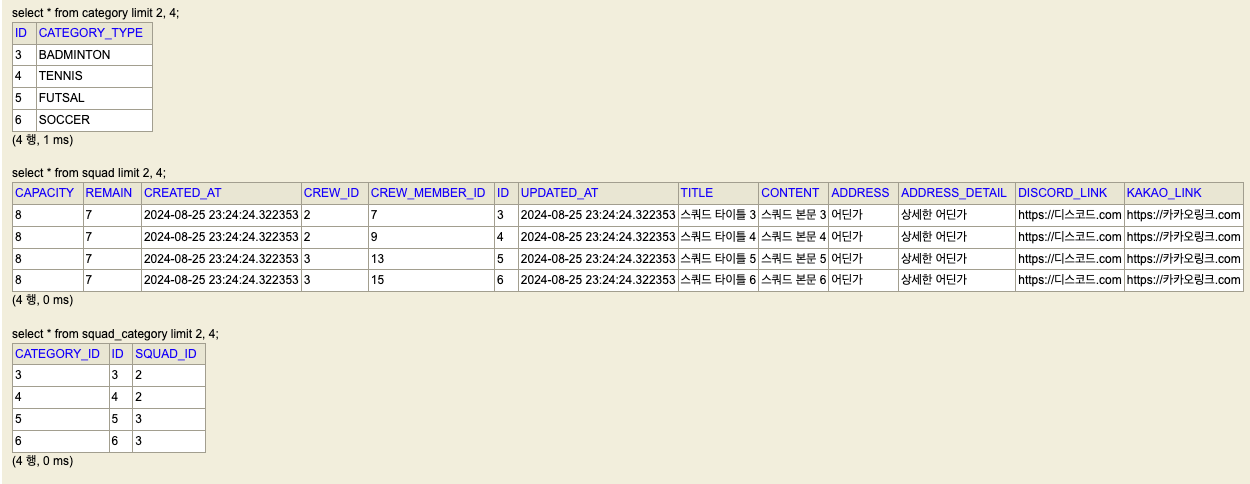
1차 정규화를 수행하고 나면, 아래와 같이 테이블을 분리할 수 있게 된다.

N:M 단순화
우리의 애플리케이션에서는 Squad 라는 엔티티가 Category 를 사용하며 하나의 Squad 에는 여러 Category 가 속할 수 있고, 하나의 Category 는 여러 Squad 에 속할 수 있다. 따라서 이는 N:M 관계가 된다.
하지만 N:M 관계는 복잡한 쿼리가 나가는 것은 물론이고, 확장성에도 좋지 않기 때문에, Squad 와 Category 의 관계 사이에 중간 테이블을 두어 Squad, SquadCategory, Category 와 같이 3개의 테이블로 풀어주어야 한다. 물론 SquadCategory 에는 Squad 와 Category 의 PK 를 FK 로 갖고 있어야 한다.
구체적으로 말하면 N:M 관계였던 Squad 와 Category 를 Squad 와 SquadCategory (1:N), Category 와 SquadCategory (1:N) 으로 분리시킨 것이다.
@Getter
@NoArgsConstructor(access = AccessLevel.PROTECTED)
@Entity
public class SquadCategory {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@ManyToOne(fetch = FetchType.LAZY)
@JoinColumn(name = "squad_id", nullable = false)
private Squad squad;
@ManyToOne(fetch = FetchType.LAZY)
@JoinColumn(name = "category_id", nullable = false)
private Category category;
}Insert 는 어떻게?
Squad 하나를 영속화하려면 Squad 정보와 N 개의 카테고리 수만큼 SquadCategory 를 영속화시켜주어야 한다. 만약 Squad 에 속한 카테고리가 5개면, 총 6 개의 Insert 쿼리가 나가게 된다. Insert 쿼리가 나가는 것이 싫다면, 아래와 같이 JdbcTemplate 를 사용해서 BatchInsert 를 사용하여 해결할 수 있다.
@RequiredArgsConstructor
@Repository
public class SquadCategoryJdbcRepository {
private final JdbcTemplate jdbcTemplate;
public void batchInsertSquadCategories(Long squadId, List<Category> categories) {
String sql = "INSERT INTO squad_category(squad_id, category_id) VALUES (?, ?)";
jdbcTemplate.batchUpdate(
sql,
categories,
categories.size(),
(ps, category) -> {
ps.setLong(1, squadId);
ps.setLong(2, category.getId());
}
);
}
}조회는 어떻게?
기준 테이블이 Squad 이라 가정했을 때, SquadCategory 가 없는 Squad 를 조회에 포함하고 싶다면 LeftJoin, 그게 아니라면 InnerJoin 을 사용해주면 된다. 물론 N + 1 방지를 위해 fetch join 이 필요하다. 이 때 주의할 것은 OneToMany 즉, Collection fetch join 이라면 Paging 시 @BatchSize 로 한번에 가져올 SquadCategory 개수를 제한해주어야 메모리에서 페이징되는 불상사가 일어나지 않는다.
테이블 확인
Squad, SquadCategory, Category 를 확인해보면 잘 분리된 것을 확인할 수 있다.